
A Comparative Study of Deep Learning Models for Stock Price Prediction
Ayush Rajbhar 1, Rahul Kumar Gupta 1, Aman Chaudhary 1, Abhishek Kumar 1, Ranjeet Kumar Dubey 1
1 Department
of CSE, KIPM College of Engineering & Technology, Gida, Gorakhpur, UP,
India
|
|
|
ABSTRACT |
|
|
This research
investigates the effectiveness of five advanced deep learning models—LSTM,
Bi-LSTM, CNN-LSTM, GRU, and CNN-GRU—in forecasting stock prices. By
leveraging historical stock data from Yahoo Finance, we implement and
evaluate each model based on prediction accuracy, RMSE, MSE, and R². The
study includes detailed preprocessing steps, model architecture explanations,
hyperparameter tuning, visual performance comparisons, and result analysis.
The RMSE for all the introduced models was measured by varying the number of
epochs, Our findings show that while all models
offer valuable predictive power, hybrid architectures such as CNN-GRU
outperform others in terms of accuracy and generalization. This comprehensive
evaluation can guide future research and practical deployment of deep
learning techniques in financial forecasting. |
|||
|
Received 07 February 2025 Accepted 08 March 2025 Published 30 April 2025 DOI 10.29121/granthaalayah.v13.i4.2025.6176 Funding: This research
received no specific grant from any funding agency in the public, commercial,
or not-for-profit sectors. Copyright: © 2025 The
Author(s). This work is licensed under a Creative Commons
Attribution 4.0 International License. With the
license CC-BY, authors retain the copyright, allowing anyone to download,
reuse, re-print, modify, distribute, and/or copy their contribution. The work
must be properly attributed to its author.
|
|||
|
Keywords: LSTM, BI-LSTM, GRU, CNN-LSTM, CNN-GRU,
Stock Market Prediction, Deep Learning |
|||
1. INTRODUCTION
Prediction of stock prices has been an important area of research for a long time. While supporters of the efficient market hypothesis believe that it is impossible to predict stock prices accurately, there are formal propositions demonstrating that accurate modeling and designing of appropriate variables may lead to models using which stock prices and stock price movement patterns can be very accurately predicted. The rise of deep learning has provided powerful tools capable of modeling these complexities. This paper compares five deep learning models: LSTM, Bi-LSTM, CNN-LSTM, GRU, and CNN-GRU in predicting Google stock prices. In this research, a novel architecture is proposed through which stock forecasting is integrated with the current Deep Neural Network algorithms such as LSTM, GRU and Bi-LSTM and hybrid models i.e. CNN-LSTM and CNN-GRU using the public historical data to promote our analysis. The performance of all the models were compared by varying different parameters. Finally, through a systematic study, the best performance was achieved utilizing the Bi-LSTM.
2. RELATED WORK
Numerous studies have leveraged machine learning for financial forecasting. Traditional methods like ARIMA and SVM have been replaced by RNN-based models due to their superior ability to capture temporal dependencies. LSTM has gained popularity for its long memory capabilities. Recent research has explored hybrid models like CNN-LSTM and CNN-GRU to incorporate both spatial and sequential patterns, offering promising results. Recent advancements in financial time series forecasting have shown the promising role of deep learning. Kumar et al. (2020) used LSTM for predicting stock movements and found a significant improvement over traditional machine learning techniques. Zhang et al. (2019) applied a Bi-LSTM model and demonstrated that bidirectional context helps in better capturing temporal dependencies. Another work by Chen et al. (2021) proposed a CNN-LSTM hybrid model that combined convolutional feature extraction with LSTM sequence learning, outperforming pure LSTM in most test cases. Furthermore, a study by Li and Zhang (2022) introduced a CNN-GRU model which achieved lower error rates and better generalization due to its hybrid structure. The LSTM model is proposed in many research to forecast stock prices, LSTM is an RNN architecture used in Natural Language Processing (NLP). The results showed that the more parameters and epochs it gets, the better performance it gives. These studies form the foundation and motivation for the comparative analysis conducted in this paper.
3. METHODOLOGY
Figure 1
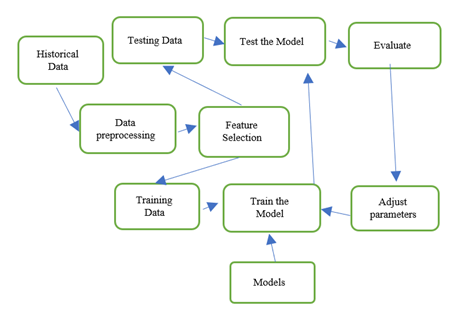
|
Figure 1 Proposed Architecture Flow Diagram |
3.1. Historical Data Collection and Preprocessing
The data is collected from the yahoo finance which is publicly available. To conduct this experiment, Google stock market data of 10 years is used . The format of the input data is numeric. The data consist of everyday’s opening value, high value, low value, closing value and volume of the stock to predict future data. Google colaboratory is used with GPU, windows 11 OS, and 8 GB RAM as a simulation environment in our research. The data was normalized using MinMaxScaler.
3.2. Feature Engineering
Technical indicators such as SMA-50, SMA-200, and RSI were added to enrich the dataset. These indicators provide insights into trends and market strength.
3.3. Training and Layered Architecture of models
LSTM: The model consists of an initial LSTM layer with 100 units, followed by a second LSTM layer with 50 units. Both layers employ L2 regularization (λ=0.001) and are followed by dropout layers (rate=0.3) to prevent overfitting. A fully connected Dense layer with 25 neurons and ReLU activation precedes the final output layer, which is a single neuron for regression output.
Bi-LSTM: A Bidirectional LSTM (Bi-LSTM) model was constructed to capture both past and future temporal dependencies in stock price sequences. The architecture includes two stacked Bi-LSTM layers with 100 and 50 units, respectively. L2 regularization (λ=0.001) is applied to both layers to mitigate overfitting. Dropout layers with a rate of 0.3 follow each recurrent layer for further regularization. A Dense layer with 25 neurons and ReLU activation precedes the output layer, which contains a single neuron for regression prediction.
CNN-LSTM: A hybrid CNN-LSTM model was employed to enhance the temporal feature extraction for stock price prediction. The model begins with a 1D convolutional layer comprising 64 filters with a kernel size of 3 and ReLU activation. This is followed by two LSTM layers with 100 and 50 units respectively, both using L2 regularization (λ=0.001). Dropout layers with a 0.3 rate are inserted after each LSTM to prevent overfitting. A Dense layer with 25 neurons and ReLU activation processes the extracted features, followed by a final output layer with a single neuron for regression
GRU: We implemented a deep learning model based on the Gated Recurrent Unit (GRU) architecture for stock price forecasting. The model comprises two stacked GRU layers with 100 and 50 units respectively. Both layers use L2 regularization (λ=0.001) and are followed by dropout layers (rate=0.3) to reduce overfitting. A dense layer with 25 ReLU-activated neurons processes the recurrent features, and a final output layer with a single neuron performs the regression prediction.
CNN-GRU: A CNN-GRU hybrid model was developed to leverage both spatial and sequential feature learning for stock price prediction. The architecture begins with a 1D convolutional layer with 64 filters (kernel size = 3) and ReLU activation. This is followed by two stacked GRU layers with 100 and 50 units respectively, each incorporating L2 regularization (λ=0.001) to reduce overfitting. Dropout layers (rate = 0.3) are added after each GRU layer to enhance generalization. A fully connected Dense layer with 25 ReLU-activated units precedes the final output layer, which contains a single neuron for regression output
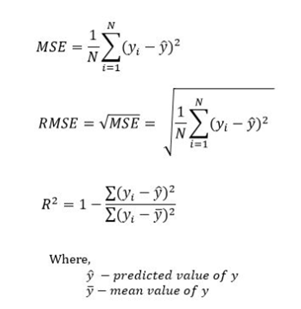
3.4. Evaluation Matrices
RMSE: Root mean squared error (RMSE) is the square root of the mean of the square of all of the errors. RMSE is considered an excellent general-purpose error metric for numerical predictions. Here, the original value, and predicted value are denoted by yi and ỳi respectively, and n represents the total amount of data.
MSE: Mean squared error (MSE) is a metric used to measure the average squared difference between the predicted values and the actual values in the dataset. It is calculated by taking the average of the squared residuals, where the residual is the difference between predicted value and the actual value for each data point.
R2: A statistical measure in a regression model that determines the proportion of variance in the dependent variable that can be explained by the independent variable. In other words, r-squared shows how well the data fit the regression model.
4. RESULT ANALYSIS
After proper scaling, training, and testing between the real data, and predicted data, we observed different types of RMSE, MSE, R2 by using different epochs for the output prediction. After analysing these different epochs for proposed models, it was came to realize that the training epochs should be chosen in the best way to train the model. Here Table 1 it can be seen that GRU model has lower RMSE of 5.941 than LSTM, CNN-GRU, CNN-LSTM and Bi-LSTM model.
Table 1
|
Table 1 Comparison of RMSE Between Different Models |
|||||
|
Epochs |
LSTM |
Bi-LSTM |
CNN-LSTM |
GRU |
CNN-GRU |
|
10 |
8.603 |
15.87 |
9.757 |
11.894 |
11.855 |
|
25 |
13.336 |
11.479 |
16.217 |
5.941 |
6.148 |
|
50 |
6.511 |
13.592 |
13.592 |
8.661 |
7.192 |
|
70 |
7.803 |
6.335 |
14.225 |
8.77 |
9.681 |
It is found that Bi-LSTM with 70 epochs, GRU with 25 epochs and CNN-GRU with 25 epochs has the highest R2 value, which is clearly mentioned in Table 2 and Table 3 represents the MSE of the models in which GRU has the lowest than others.
Table 2
|
Table 2 Comparison of R2
Between Different Models |
|||||
|
Epochs |
LSTM |
Bi-LSTM |
CNN-LSTM |
GRU |
CNN-GRU |
|
10 |
0.83 |
0.46 |
0.79 |
0.67 |
0.67 |
|
25 |
0.59 |
0.72 |
0.39 |
0.91 |
0.91 |
|
50 |
0.9 |
0.57 |
0.57 |
0.83 |
0.88 |
|
70 |
0.87 |
0.91 |
0.53 |
0.82 |
0.78 |
Table 3
|
Table 3 Comparison of MSE Between Different Models |
|||||
|
Epochs |
LSTM |
Bi-LSTM |
CNN-LSTM |
GRU |
CNN-GRU |
|
10 |
74.024 |
251.85 |
95.217 |
141.48 |
140.5 |
|
25 |
177.86 |
131.77 |
263.01 |
35.3 |
37.8 |
|
50 |
42.4 |
184.75 |
184.75 |
75.024 |
51.73 |
|
70 |
60.897 |
40.132 |
202.36 |
76.917 |
93.72 |
From the above comparison tables it can be noted that GRU has lowest RMSE and highest R2 score than others and in Table 4, which is accuracy table, Bi-LSTM has the highest accuracy with 70 epochs.
Table 4
|
Table 4 Comparison of Accuracy Between Different Models |
|||||
|
Epochs |
LSTM |
Bi-LSTM |
CNN-LSTM |
GRU |
CNN-GRU |
|
10 |
88.07 |
94.32 |
89.08 |
93.49 |
91.32 |
|
25 |
75.05 |
94.32 |
66.38 |
93.06 |
91.76 |
|
50 |
91.32 |
94.36 |
68.55 |
94.77 |
95.21 |
|
70 |
91.92 |
95.23 |
68.33 |
95.22 |
94.78 |
The figures mentioned below represents the graph between actual and predicted stock price of Google. The graph consist of test data which provide the visual understanding of accuracy between different models with different epochs.
Figure 2
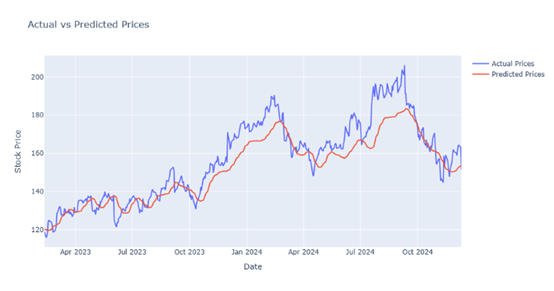
|
Figure 2 Output prediction for 10 epochs by LSTM model |
Figure 3
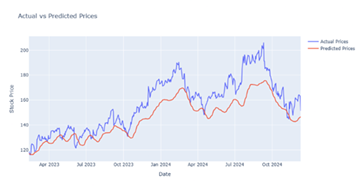
|
Figure 3 Output Prediction for 25 Epochs by LSTM Model |
Figure 4
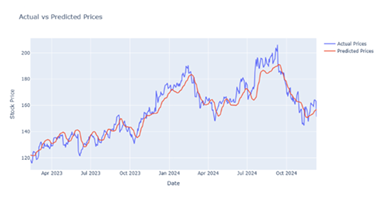
|
Figure 4 Output Prediction for 50 Epochs by LSTM Model |
Figure 5
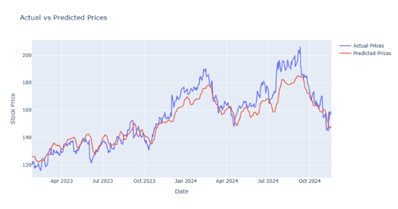
|
Figure 5 Output Prediction for 70 Epochs by LSTM Model |
Figure 6
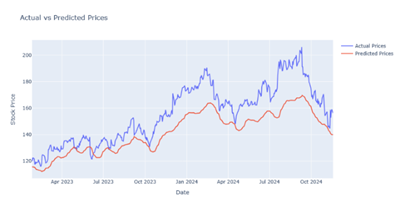
|
Figure 6 Output Prediction for 10 Epochs by Bi-LSTM Model |
Figure 7
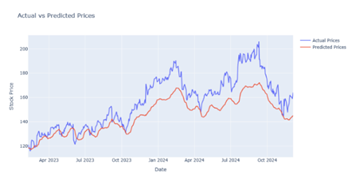
|
Figure 7 Output Prediction for 25 Epochs by Bi-LSTM Model |
Figure 8

|
Figure 8 Output Prediction for 50 Epochs by Bi-LSTM Model |
Figure 9
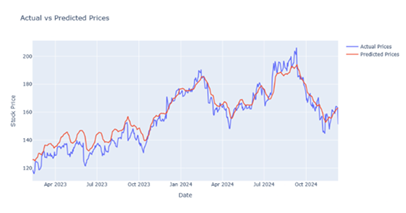
|
Figure 9 Output Prediction for 70 Epochs by Bi-LSTM Model |
Figure 10

|
Figure 10 Output Prediction for 10 Epochs by CNN-LSTM Model |
Figure 11

|
Figure 11 Output Prediction for 25 Epochs by CNN-LSTM Model |
Figure 12
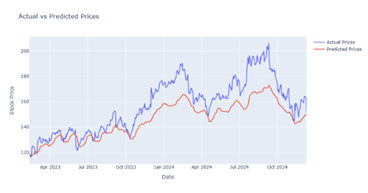
|
Figure 12 Output Prediction for 50 Epochs by CNN-LSTM Model |
Figure 13
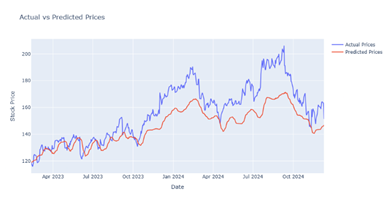
|
Figure 13 Output Prediction for 70 Epochs by CNN-LSTM Model |
Figure 14

|
Figure 14 Output Prediction for 10 Epochs by GRU Model |
Figure 15
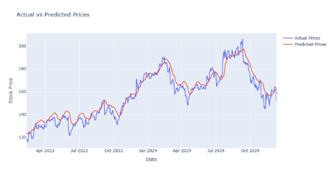
|
Figure 15 Output Prediction for 25 Epochs by GRU Model |
Figure 16
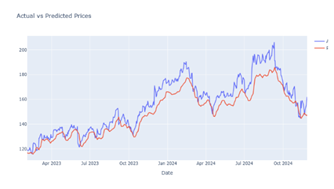
|
Figure 16 Output Prediction for 50 Epochs by GRU Model |
Figure 17
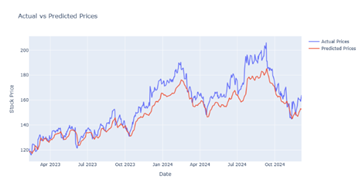
|
Figure 17 Output Prediction for 70 Epochs by GRU Model |
Figure 18
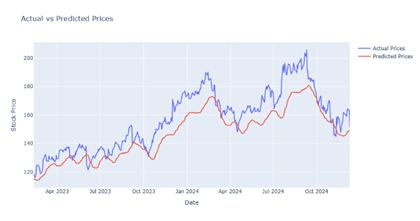
|
Figure 18 Output Prediction for 10 Epochs by CNN-GRU Model |
Figure 19
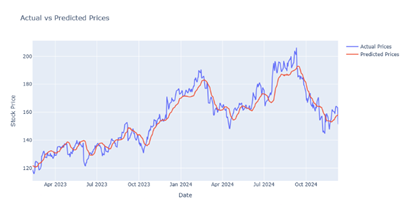
|
Figure 19 Output Prediction for 25 Epochs by CNN-GRU Model |
Figure 20
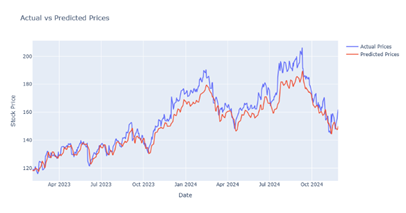
|
Figure 20 Output Prediction for 50 Epochs by CNN-GRU Model |
Figure 21
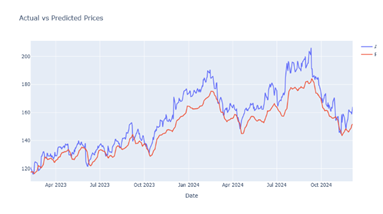
|
Figure 21 Output Prediction for 70 Epochs by CNN-GRU Model |
After performing a lot of training analyses and comparison among different evaluation measures it is noted that in the LSTM model, we achieved the best result for 50 epochs Figure 4, further in Bi-LSTM the best result is achieved for 70 epochs Figure 9 whereas in CNN-LSTM hybrid model the best result is achieved for 10 epochs Figure 10. In GRU and CNN-GRU the best results are achieved for 25 epochs Figure 15 & Figure 19.
5. CONCLUSION
This study presents a comprehensive comparative analysis of five deep learning models-LSTM, Bi-LSTM, CNN-LSTM, GRU, and CNN-GRU, for stock price prediction using historical Google stock data. Each model was evaluated using key regression metrics including RMSE, MSE, and R² across multiple epochs. Our experimental results reveal that while all models demonstrate significant predictive capabilities, the GRU model with 25 epochs consistently achieved the lowest RMSE (5.941) and MSE (35.30), alongside a high R² score (0.91). The CNN-GRU hybrid model also performed competitively, balancing both spatial and sequential learning mechanisms. Interestingly, the Bi-LSTM model delivered the highest prediction accuracy (95.23%) at 70 epochs, indicating its strength in capturing bidirectional temporal dependencies.
CONFLICT OF INTERESTS
None.
ACKNOWLEDGMENTS
None.
REFERENCES
Aadhitya, A., Rajapriya, R., Vineetha, R. S., & Bagde, M. A. (2023). Predicting Stock Market Time-Series Data Using CNN-LSTM Neural Network Model. Arxiv Preprint arXiv:2305.14378. https://arxiv.org/abs/2305.14378
Alkhatib, K., Khazaleh, H., Alkhazaleh, H. A., Alsoud, A. R., & Abualigah, L. (2022). A New Stock Price Forecasting Method Using Active Deep Learning Approach. Journal of Open Innovation: Technology, Market, and Complexity, 8(2), 96. https://doi.org/10.3390/joitmc8020096
Bansal, M., Goyal, A., & Choudhary, A. (2022). Stock Market Prediction with High Accuracy Using Machine Learning Techniques. Procedia Computer Science, 215, 247–265. https://doi.org/10.1016/j.procs.2022.12.028
Chen, X. (2023). Stock Price Prediction Using Machine Learning Strategies. BCP Business & Management, 36, 488–497. https://doi.org/10.54691/bcpbm.v36i.3507
Liu, H. (2025). A Hybrid CNN-LSTM Approach for Effective Stock Price Prediction in Optimizing Investment Strategies. Proceedings of the International Conference on Data Engineering and Business Analytics (ICDEBA 2024)*, 456–462. Atlantis Press. https://www.atlantis-press.com/proceedings/icdeba-24/126008575
Rahmadeyan, A., & Mustakim. (2022). Long Short-Term Memory and Gated Recurrent unit for Stock Price Prediction. Procedia Computer Science, 199, 1057–1066.
Safari, A., & Badamchizadeh, M. A. (2024). DeepInvesting: Stock Market Predictions with a Sequence-Oriented BiLSTM Stacked Model – A Dataset Case Study of AMZN. Intelligent Systems with Applications, 24, Article 200439. https://doi.org/10.1016/j.iswa.2024.200439
Shahi, T. B., Shrestha, A., Neupane, A., & Guo, W. (2020). Stock Price Forecasting with Deep Learning: A Comparative Study. Mathematics, 8(9), 1441. https://doi.org/10.3390/math8091441
Wibowo, A., & Rizky, N. G. (2022). Time Series Forecasting Based on Deep Learning CNN-LSTM-GRU Model on Stock Prices. SSRG International Journal of Engineering Trends and Technology, 71(6), 215–221. https://ijettjournal.org/archive/ijett-v71i6p215
 This work is licensed under a: Creative Commons Attribution 4.0 International License
This work is licensed under a: Creative Commons Attribution 4.0 International License
© Granthaalayah 2014-2025. All Rights Reserved.

