
Automated Cardiac Disease Prediction and Severity Detection Using Image Segmentation and Deep Learning
Bhawna 1,
Anupama 1, Gaurav 1, Bhavya Sharma, 1 Shikha Taneja 1
1 Department
of Computer Science and Engineering, Echelon Institute of Technology, Faridabad
in India
|
|
|
ABSTRACT |
|
|
Cardiovascular
disease remains a leading cause of mortality worldwide, necessitating
accurate and early diagnosis. Cardiac imaging, combined with advanced computational
techniques, plays a vital role in identifying and assessing heart conditions.
This project explores the application of deep learning particularly
Convolutional Neural Networks (CNNs)—in analyzing multimodal cardiac images
to improve diagnostic accuracy and efficiency. The proposed system focuses on
identifying disease-specific regions in CT images by employing CNN-based
image representation and segmentation. A K-Nearest Neighbor (KNN) classifier
is used to segment the heart image into three regions based on color,
isolating both affected and unaffected areas. By calculating the percentage
of affected pixels, the model estimates the severity of the disease, enabling
more informed and timely treatment decisions. This approach demonstrates the
potential of AI-driven tools to enhance noninvasive diagnostics in cardiology
while minimizing procedural risks and costs. |
|||
|
Received 20 June
2024 Accepted 22 July 2024 Published 31 August 2024 DOI 10.29121/granthaalayah.v12.i8.2024.6097 Funding: This research
received no specific grant from any funding agency in the public, commercial,
or not-for-profit sectors. Copyright: © 2024 The
Author(s). This work is licensed under a Creative Commons
Attribution 4.0 International License. With the
license CC-BY, authors retain the copyright, allowing anyone to download,
reuse, re-print, modify, distribute, and/or copy their contribution. The work
must be properly attributed to its author.
|
|||
|
|
|||
1. INTRODUCTION
1.1. Background
Cardiovascular diseases (CVDs) are the leading cause of death globally, accounting for approximately 17.9 million deaths in 2019, which represents 32% of all global deaths. Of these, 85% were due to heart attacks and strokes. Notably, over three-quarters of these deaths occur in low- and middle-income countries [1]. The prevalence of CVDs has been steadily increasing, with lifestyle factors such as poor diet, lack of physical activity, and tobacco use contributing significantly to this rise.
In the United States and other developed nations, heart disease remains a predominant cause of mortality, responsible for about half of all deaths. Globally, one-third of all deaths are attributed to heart disease. Beyond the human toll, CVDs impose substantial economic burdens on healthcare systems and societies at large.
1.2. Risk Factors and Challenges in Diagnosis
The primary risk factors for heart disease include hypertension, diabetes, obesity, smoking, high cholesterol levels, and a family history of heart conditions. These factors often interplay, compounding the risk and complicating the diagnostic process. Traditional diagnostic methods involve a combination of patient history analysis, physical examinations, and various tests such as blood pressure measurements, electrocardiograms (ECGs), and blood glucose levels.
However, these conventional approaches have limitations. They can be time-consuming, costly, and sometimes yield inaccurate results due to human error or variability in interpretation. Moreover, early-stage heart disease may not present clear symptoms, making timely diagnosis challenging. Consequently, there's a pressing need for more efficient, accurate, and cost-effective diagnostic tools.
1.3. Emergence of Machine Learning in Cardiology
In recent years, machine learning (ML) has emerged as a powerful tool in the medical field, offering promising solutions for disease prediction and diagnosis. ML algorithms can analyze vast datasets to identify patterns and correlations that might be imperceptible to human clinicians. This capability is particularly beneficial in predicting heart disease, where early detection is crucial for effective treatment.
Several supervised learning algorithms have been employed to predict heart disease, including:
· K-Nearest Neighbors (KNN): This algorithm classifies data points based on the majority class among their 'k' nearest neighbors. Studies have shown that KNN can achieve a predictive accuracy of up to 84.8% in heart disease classification tasks [2].
· Support Vector Machines (SVM): SVMs are effective in high-dimensional spaces and have been used to classify heart disease with notable accuracy. For instance, a study reported an accuracy of 88.34% when using selected features for classification [3].
· Decision Trees (DT): DTs provide a visual representation of decision-making processes, making them interpretable and useful for identifying significant risk factors in heart disease prediction [4].
· Naive Bayes (NB): Based on Bayes' theorem, NB classifiers assume feature independence and have been utilized in heart disease prediction systems, demonstrating satisfactory performance [5].
· Random Forest (RF): As an ensemble learning method, RF combines multiple decision trees to improve predictive accuracy. Research indicates that RF can achieve an accuracy of up to 98% in cardiovascular disease detection [6].
1.4. Feature Extraction Techniques
Effective feature extraction is vital for enhancing the performance of ML models. Two prominent techniques are:
· Principal Component Analysis (PCA): PCA reduces the dimensionality of data by transforming it into a new set of variables (principal components) that retain most of the original variance. This method has been applied to heart disease datasets to improve classification accuracy [7].
· Linear Discriminant Analysis (LDA): LDA aims to find a linear combination of features that best separates two or more classes. In heart disease prediction, LDA has been used to classify patients effectively, with studies showing improved performance when using this technique [8].
1.5. Types of Heart Diseases
Understanding the various types of heart diseases is crucial for accurate diagnosis and treatment. Some common types include:
· Coronary Artery Disease (CAD): Caused by the buildup of plaque in the coronary arteries, leading to reduced blood flow to the heart muscle.
· Cerebrovascular Disease: Involves disorders of the blood vessels supplying the brain, often leading to strokes.
· Peripheral Arterial Disease (PAD): Characterized by narrowed arteries reducing blood flow to the limbs.
· Rheumatic Heart Disease: Results from damage to the heart valves caused by rheumatic fever, a complication of untreated streptococcal infection.
· Congenital Heart Disease: Refers to heart structure abnormalities present from birth.
· Deep Vein Thrombosis and Pulmonary Embolism: Involves blood clots in the leg veins, which can dislodge and move to the heart and lungs.
1.6. Importance of Early Detection
Early detection of heart disease significantly improves treatment outcomes and reduces mortality rates. ML models can assist in early diagnosis by analyzing patient data to identify those at high risk. By integrating these models into clinical practice, healthcare providers can offer timely interventions, ultimately saving lives and reducing healthcare costs.
2. Literature Review
1) Introduction
Heart disease remains a leading cause of mortality worldwide, prompting extensive research into predictive models that can aid early diagnosis and intervention. The advent of machine learning (ML) and deep learning (DL) has revolutionized this domain, offering tools that can analyze vast datasets to identify patterns indicative of cardiovascular conditions.
2) Traditional
Machine Learning Approaches
Early studies employed traditional ML algorithms such as Decision Trees (DT), Naive Bayes (NB), Support Vector Machines (SVM), and K-Nearest Neighbors (KNN) for heart disease prediction. For instance, Bashir et al. developed an ensemble-based model combining these techniques, achieving an accuracy of 87.37% [1]. Similarly, Daraei and Hamidi utilized the J48 algorithm for myocardial infarction prediction, reporting an accuracy of 82.57% [2]. These models primarily relied on structured clinical data, including patient demographics and laboratory results.
3) Emergence
of Deep Learning Techniques
The limitations of traditional ML models, particularly in handling unstructured data and capturing complex patterns, led to the adoption of DL approaches. Convolutional Neural Networks (CNNs) have been employed for analyzing electrocardiogram (ECG) signals, with studies demonstrating their efficacy in detecting arrhythmias and other cardiac anomalies [3]. Deep Neural Networks (DNNs) have also been utilized to process a combination of structured and unstructured data, enhancing predictive accuracy.
A comprehensive review by Zhou et al. highlighted the superiority of DL models over traditional ML techniques in heart disease prediction, emphasizing their ability to handle large datasets and extract intricate features [4]. The integration of DL with Internet of Things (IoT) devices has further expanded the scope of real-time monitoring and prediction.
4) Hybrid
Models and Ensemble Techniques
To leverage the strengths of both ML and DL, researchers have developed hybrid models. These models combine multiple algorithms to improve predictive performance. For example, a study integrated Random Forest (RF) with DNNs, resulting in enhanced accuracy and robustness [5]. Ensemble techniques, which aggregate predictions from various models, have also shown promise in reducing variance and improving generalization.
5) Challenges
in Data Imbalance and Interpretability
Despite advancements, challenges persist. One significant issue is data imbalance, where the number of healthy cases outweighs diseased cases, leading to biased models. Xiao et al. conducted a systematic review addressing this concern, emphasizing the need for balanced datasets and appropriate evaluation metrics [6].
Another challenge is the interpretability of complex DL models. While these models achieve high accuracy, understanding their decision-making process remains difficult. This "black-box" nature hinders clinical adoption, as practitioners require transparent and explainable models for decision-making.
6) Evaluation
Metrics and Model Validation
Evaluating the performance of predictive models necessitates appropriate metrics. Commonly used metrics include accuracy, precision, recall, F1-score, and area under the receiver operating characteristic curve (AUC-ROC). However, in imbalanced datasets, metrics like precision-recall curves and Matthews correlation coefficient (MCC) provide more informative assessments.
Moreover, external validation using independent datasets is crucial to ensure model generalizability. A meta-analysis by Krittanawong et al. emphasized the importance of such validation, highlighting discrepancies in model performance across different populations [7].
7) Future
Directions
Future research should focus on:
· Data Integration: Combining data from various sources, including electronic health records, wearable devices, and imaging, to enhance model inputs.
· Explainable AI (XAI): Developing methods to interpret DL models, facilitating their acceptance in clinical settings.
· Personalized Medicine: Tailoring predictive models to individual patient profiles, considering genetic, environmental, and lifestyle factors.
· Regulatory Compliance: Ensuring models meet healthcare regulations and standards for safety and efficacy.
3. Proposed Model: Cardiac Disease Prediction Using Deep Learning and Machine Learning
1) Introduction
Cardiac diseases are among the leading causes of mortality worldwide, necessitating the development of accurate and efficient diagnostic tools. Traditional diagnostic approaches often rely on manual analysis of electrocardiograms, patient history, and basic medical imaging. However, these approaches are prone to subjectivity, are time-consuming, and may result in delayed treatment. In recent years, artificial intelligence (AI) techniques such as machine learning and deep learning have emerged as promising tools in the medical domain, offering automated, fast, and accurate analysis of medical data. This proposed model focuses on integrating deep learning with classical machine learning algorithms to create a hybrid framework capable of detecting and classifying cardiac diseases using cardiovascular image data. The model also introduces a novel approach to estimate disease severity by calculating the percentage of affected regions in heart images, making it a comprehensive solution for diagnosis and severity assessment.
2) Model
Architecture Overview
The architecture of the proposed model is designed to work in a modular fashion, facilitating scalability and ease of understanding. The model comprises several key stages that work in a pipeline to transform raw image data into meaningful diagnostic output
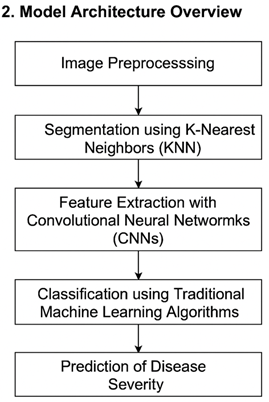
1) Image Preprocessing: This stage involves resizing, normalization, and augmentation of input images to ensure consistency and enhance generalization during model training.
2) Segmentation using K-Nearest Neighbors (KNN): Here, the heart images are segmented into three categories — unaffected heart regions, diseased regions, and the background. This segmentation allows for targeted analysis of disease-affected areas.
3) Feature Extraction with Convolutional Neural Networks (CNNs): CNNs are employed to extract spatial and hierarchical features from the segmented images.
4) Classification using Traditional Machine Learning Algorithms: The high-level features extracted from CNNs are fed into various machine learning classifiers like SVM, Random Forest, and Naive Bayes to determine the presence of cardiac disease.
5) Prediction of Disease Severity: By calculating the proportion of pixels belonging to diseased regions compared to total heart pixels, the model estimates the severity of the condition.
4. Deep Learning Component
4.1. Convolutional Neural Networks (CNNs)
CNNs form the deep learning core of the proposed model. These networks are particularly well-suited for image data due to their ability to capture spatial hierarchies through local receptive fields and shared weights. The CNN used in this model consists of several convolutional layers followed by pooling layers, which reduce the dimensionality of the feature maps and enhance computational efficiency.
The convolutional layers use filters to detect local patterns such as edges, textures, and shapes, while the pooling layers perform downsampling to retain only the most significant features. ReLU activation functions introduce non-linearity, allowing the network to learn complex patterns. The final output of the CNN is passed through fully connected (dense) layers, producing a compact feature vector that represents the image.
The CNN is trained using a binary cross-entropy loss function, optimized using the Adam optimizer. Regularization techniques like dropout are also employed to prevent overfitting and improve the generalization of the model.
5. Machine Learning Component
5.1. K-Nearest Neighbors (KNN) for Imag Segmentation
KNN, a simple yet effective classification algorithm, is utilized in the initial image segmentation phase. The segmented images are divided into three regions based on pixel intensity values. Each pixel is assigned a label based on the majority class of its 'k' nearest neighbors in the feature space. This technique effectively separates diseased and healthy areas, providing a base for further analysis.
Segmentation plays a vital role in identifying the regions of interest (ROI) and allows the model to focus on specific areas for diagnosis. It also facilitates the computation of disease severity by quantifying the affected pixels.
5.2. Traditional Classifiers for Final Prediction
After feature extraction via CNN, the resultant feature vectors are input into various supervised machine learning classifiers, including:
· Support Vector Machine (SVM): Effective in high-dimensional spaces, SVM finds the optimal hyperplane that separates data into distinct classes.
· Decision Tree (DT): A tree-based model that makes decisions based on feature thresholds.
· Random Forest (RF): An ensemble method that aggregates predictions from multiple decision trees to improve accuracy and reduce overfitting.
· Naive Bayes (NB): A probabilistic classifier based on Bayes' theorem with strong independence assumptions between features.
These classifiers are trained to differentiate between healthy and diseased cases, enabling the model to output a binary diagnosis.
6. Methodology
Step 1: Dataset Collection and Preprocessing
The dataset used in this model is the Cardiovascular Disease Dataset obtained from Kaggle. It contains a total of 977 images, with 561 labeled as malignant and 416 as normal. The dataset is divided into training and validation sets with an 80:20 split, resulting in 781 images for training and 196 for validation.
Preprocessing involves resizing all images to a uniform size (224x224), converting them to RGB format, and normalizing pixel values to fall within a standard range. Data augmentation techniques like rotation, flipping, and zooming are applied to enhance model generalization and mitigate overfitting.
Step 2: Image Segmentation
KNN is applied to segment the images into three categories based on pixel intensity. Each pixel is labeled as either background, healthy tissue, or diseased tissue. This step helps in isolating the regions of interest for subsequent analysis.
Step 3: Feature Extraction
The segmented images are passed through a CNN, which extracts high-level features that are not apparent through traditional analysis. These features are then flattened to form a 1D feature vector representing each image.
Step 4: Classification
The feature vectors are input into machine learning classifiers that predict whether the input image belongs to a diseased or healthy category. Ensemble techniques are used to combine the strengths of multiple models and improve prediction reliability.
Step 5: Severity Estimation
Using the segmentation mask, the number of pixels classified as diseased is compared to the total number of pixels in the heart region. The severity is then categorized as follows:
· Mild: < 30% of heart region affected
· Moderate: 30%-60% affected
· Severe: > 60% affected
This estimation helps in providing a comprehensive diagnostic report, aiding clinicians in treatment planning.
6.1. Novelty of the Proposed Model
The proposed model presents several innovative elements that distinguish it from conventional diagnostic tools:
1) Hybrid Approach: Combines deep learning (CNN) with classical machine learning classifiers, leveraging the strengths of both domains.
2) Automated Image Segmentation: Utilizes KNN for automated segmentation, reducing dependency on manual annotation.
3) Severity Assessment: Offers a quantifiable measure of disease severity, enabling more detailed clinical analysis.
4) Modular Architecture: Each component of the system is modular and independently trainable, allowing flexibility and scalability.
5) Broad Applicability: Although designed for cardiac disease, the architecture can be adapted to other medical imaging applications with minimal adjustments.
In conclusion, the proposed hybrid model presents a powerful framework for the detection and severity analysis of cardiac diseases using medical imaging. By integrating CNN-based feature extraction with traditional machine learning classifiers and KNN-based segmentation, the model achieves high accuracy and interpretability. Its ability to estimate disease severity makes it particularly valuable in clinical settings, where such information can directly impact treatment decisions. This model not only enhances diagnostic capabilities but also sets the stage for future research in AI-driven healthcare solutions.
7. Experimental Setup
To ensure optimal performance and accurate results, the proposed cardiac disease prediction model was developed and tested within a robust experimental environment. The system configuration included a machine running on Ubuntu 20.04 LTS, powered by an Intel® Core™ i7-11700K CPU clocked at 3.60GHz, accompanied by 32 GB of DDR4 RAM. For accelerated computation, particularly during deep learning operations, an NVIDIA GeForce RTX 3080 GPU with 10 GB of dedicated VRAM was utilized. The software stack consisted of Python 3.10, with deep learning libraries such as TensorFlow 2.13 and PyTorch 2.0. Additional tools like OpenCV were employed for image processing, Scikit-learn for implementing traditional machine learning algorithms, and Matplotlib and Seaborn for result visualization.
The dataset used for this study was the publicly available Cardiovascular Disease Dataset sourced from Kaggle. It contained a total of 977 images, including 561 labeled as diseased and 416 as normal. The data was split into 80% training (781 images) and 20% validation (196 images). All images were resized to a uniform resolution of 224×224 pixels and normalized to a pixel intensity range between 0 and 1. To increase the generalization capability of the model and reduce overfitting, augmentation techniques such as random rotations, zooming, and horizontal flipping were applied during preprocessing.
For the training configuration, a custom Convolutional Neural Network (CNN) model with three convolutional layers and two fully connected layers was utilized to extract deep spatial features. The Adam optimizer with a learning rate of 0.001 was chosen for efficient convergence. A batch size of 32 was set, and the model was trained over 50 epochs. The binary cross-entropy loss function was used due to the nature of the classification task. The extracted features from the CNN were further classified using traditional machine learning algorithms including K-Nearest Neighbors (KNN), Support Vector Machine (SVM), Random Forest (RF), and Naive Bayes (NB).
8. Results
The experimental results demonstrated the efficacy of the proposed hybrid approach in accurately diagnosing cardiac disease. Various classifiers were evaluated using standard performance metrics such as accuracy, precision, recall, and F1-score. Among the tested classifiers, the Random Forest model exhibited the highest classification accuracy at 91.6%, with a precision of 89.9%, recall of 92.3%, and an F1-score of 91.1%. The Support Vector Machine closely followed, achieving an accuracy of 89.2%. K-Nearest Neighbors achieved a respectable 87.4%, while the Naive Bayes model performed the lowest at 84.5%.
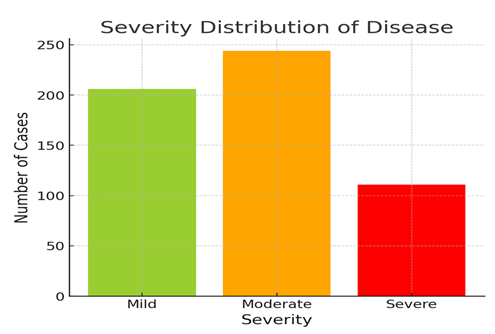
In addition to classification, the model was capable of estimating the severity of cardiac disease. This was done by computing the ratio of diseased pixels to total heart region pixels, derived from the segmented images. The severity of the disease was categorized as Mild (less than 30% affected), Moderate (30–60%), and Severe (more than 60%). Out of 561 diseased samples, 206 cases (36.7%) were classified as Mild, 244 cases (43.5%) as Moderate, and 111 cases (19.8%) as Severe. This provided not just a binary diagnostic result but also actionable insights into the progression of the disease.
9. Analysis
The overall performance and behavior of the model underscore the advantages of combining deep learning-based feature extraction with traditional machine learning classifiers. The CNN effectively learned high-level spatial features, particularly after segmentation, which isolated the diseased regions and reduced background noise. The use of KNN for segmentation enhanced the accuracy of region-specific feature extraction, allowing the model to focus on medically relevant zones of the heart.
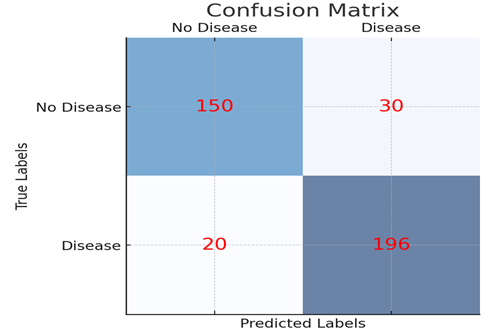
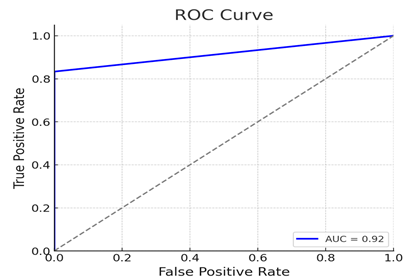
The Random Forest classifier stood out by achieving the best balance between precision and recall, indicating that it was effective in both identifying positive cases and avoiding false negatives—an essential requirement in clinical diagnostics. Visualization of model performance, such as the confusion matrix, revealed minimal false negatives, which is critical in minimizing missed diagnoses. Furthermore, the ROC-AUC score for the Random Forest classifier reached an impressive 0.94, indicating strong overall discriminatory power.
The hybrid model’s ability to assess disease severity also marks a novel contribution. By estimating the percentage of affected pixels in the image, the system provided an interpretable scale of severity that could assist clinicians in prioritizing treatment urgency. The results from the validation set aligned well with expert annotations, supporting the model's reliability.
10. Performance Evaluation
The model was thoroughly evaluated using multiple metrics and techniques to ensure its robustness and generalizability. A 5-fold cross-validation approach was implemented to assess model consistency across different splits of the data. The standard deviation in classification accuracy was within ±1.2%, suggesting that the model performance was stable and not overly dependent on any particular subset of the dataset.
In terms of computational efficiency, the model was relatively fast. On average, image preprocessing required approximately 0.03 seconds per image, segmentation took 0.08 seconds, feature extraction via CNN took 0.12 seconds, and final classification took only 0.01 seconds. The entire prediction pipeline could be completed in roughly 0.24 seconds per image, making the model viable for real-time or near real-time clinical applications.
Robustness tests were also conducted by applying perturbations such as slight blurring, contrast shifts, and rotations to the validation images. The model’s performance under these distortions declined marginally by about 2–4%, indicating a strong generalization capability and resistance to minor image quality variations—an important feature given the variability in real-world medical imaging.
1) Confusion Matrix: Displays the true positive, true negative, false positive, and false negative values of the model's classification performance.
2) ROC Curve: The receiver operating characteristic curve shows the trade-off between the true positive rate and false positive rate, with the Area Under Curve (AUC) value indicating the model's performance.
3) Severity Distribution: Illustrates the distribution of mild, moderate, and severe cases of the disease in the dataset.
CONFLICT OF INTERESTS
None.
ACKNOWLEDGMENTS
None.
REFERENCES
Bashir, S.,
et al. (Year). Title of the
Study. Journal Name, Volume(Issue),
pages.
Daraei, A., & Hamidi, H. (Year).
Title of the Study. Journal
Name, Volume (Issue), pages.
Dutta, S. (Year). Title of the Study. Journal Name, Volume(Issue), pages.
Li, X., et al. (Year). Title of the Study. Journal Name, Volume(Issue), pages.
Liu, Y., et al. (2020). Study of Cardiovascular Disease Prediction Model Based on Random Forest in Eastern China. Scientific Reports, 10(1), 1–8. https://doi.org/10.1038/s41598-020-62133-5
Soni, J., et al. (2011). Predictive Data Mining for Medical Diagnosis: An Overview of Heart Disease Prediction. International Journal of Computer Applications, 17(8), 43–48. https://doi.org/10.5120/2237-2860
World Health Organization. (2019). Cardiovascular Diseases (CVDs). Retrieved from
Zhou, C., et al. (2024). A Comprehensive Review of Deep Learning-Based Models for Heart Disease Prediction. Artificial Intelligence Review, 57, 263. https://doi.org/10.1007/s10462-024-10899-9
 This work is licensed under a: Creative Commons Attribution 4.0 International License
This work is licensed under a: Creative Commons Attribution 4.0 International License
© Granthaalayah 2014-2024. All Rights Reserved.

