ShodhKosh: Journal of Visual and Performing ArtsISSN (Online): 2582-7472
|
|
Emotion-Driven Generative Systems Producing Personalized Visual Art Based on User Preferences
Prasanna Kumar E 1![]() , Kiran Ingale 2
, Kiran Ingale 2![]() , Damodaran
B 3
, Damodaran
B 3![]() , Mistry
Roma Lalitchandra 4
, Mistry
Roma Lalitchandra 4![]()
![]() , Dr.
Rahul Amin 5
, Dr.
Rahul Amin 5![]()
![]() , Simran Kalra 6
, Simran Kalra 6![]()
![]()
1 Assistant
Professor, Meenakshi College of Arts and Science, Meenakshi Academy of Higher
Education and Research, Chennai, Tamil Nadu 600080, India
2 Assistant
Professor, Department of E&TC Engineering, Vishwakarma Institute of
Technology, Pune, Maharashtra, 411037, India
3 Associate Professor, Psychology, Meenakshi College of Arts and
Science, Meenakshi Academy of Higher Education and Research, Chennai, Tamil
Nadu 600080, India
4 Assistant Professor, Department of Design, Vivekananda Global
University, Jaipur, India
5 Associate Professor, Department of Journalism and Mass Communication,
ARKA JAIN University, Jamshedpur, Jharkhand, India
6 Centre of Research Impact and Outcome, Chitkara University, Rajpura
140417, Punjab, India
|
|
|
ABSTRACT |
|
|
Generative
systems that are based on emotions are a revolutionary approach in
computational creativity because they allow the user to create visual
artworks that are specific to the user and their emotional state. This paper
will suggest a unified system wherein multimodal emotion recognition is
integrated with powerful generative models to generate adaptive and
expressive works of art. The system combines various modalities of inputs
like facial expressions, voice signals and physiological data, and it detects
and encodes emotions using deep learning networks such as convolutional
neural networks (CNNs), long short-term memory (LSTM) networks and
transformer based networks. An organized algorithmic sequence is proposed,
including the parameterization, real time emotion recognition, feature
encodings, and art creation that is adaptive. The experimental tests reveal
dramatic enhancement of the accuracy of personalization, consistency in
emotions, and interactivity when compared to conventional non-interactive systems
of art. The results of visualization and case studies also prove the
possibility of the system to dynamically change the artistic styles, color
palette and compositions based on the preferences of particular users. This
study presents the possibilities of emotion-sensitive generative models to
reconfigure human-machine co-creation, provide scalable approaches to
interactive digital art, therapeutic and immersive user-centered design
spaces. |
|||
|
Received 14 January 2026 Accepted 29 March
2026 Published 11 April 2026 Corresponding Author Prasanna
Kumar E, kumar@maher.ac.in DOI 10.29121/shodhkosh.v7.i4s.2026.7496 Funding: This research
received no specific grant from any funding agency in the public, commercial,
or not-for-profit sectors. Copyright: © 2026 The
Author(s). This work is licensed under a Creative Commons
Attribution 4.0 International License. With the
license CC-BY, authors retain the copyright, allowing anyone to download,
reuse, re-print, modify, distribute, and/or copy their contribution. The work
must be properly attributed to its author.
|
|||
|
Keywords: Emotion-Driven Generation, Affective Computing,
Personalized Visual Art, Multimodal Emotion Recognition, Generative
Adversarial Networks (Gans), Human–AI Co-Creation |
|||


1. INTRODUCTION
The fast development of artificial intelligence and computational creativity has dramatically changed the environment in modern visual art, as machines are more than capable of participating in the artistic process. One of these developments is the emotion-driven generative systems which have become a promising paradigm which balances the human affective state with the generation of algorithmic content. Unlike the old generative art systems, which are dependent on preset rules or fixed inputs, emotional responsive systems vary outputs in response to the user in real time based on their current emotions, which creates a level of customization and experience that goes further. This trend indicates a wider change towards the human-centred AI, where the systems are developed not only to execute functions but also to empathise and react to human experiences. Emotion is a core component of the artistic experience and perception, and it affects the way people make, perceive, and relate to visual information Li et al. (2023). When emotional intelligence is incorporated into generative systems, it is possible to create works of art that can appeal more to the users and improve their aesthetic quality and experience. The recent progress on affective computing has been used to detect and classify human emotions with precision using the multimodal data sources such as facial expressions, speech patterns, physiological evidences such as heart rate variability and galvanic skin response. With deep learning methods, visual feature representation based on convolutional neural networks (CNNs), temporal sequence modeling with long short-term memory (LSTM) networks, and more intricate contextual dependency than either sequencing have transformed these streams of data into useful features, products, or services Ali et al. (2023).
At the same time, advanced generative modeling applications like generative adversarial networks (GANs) and diffusion-based models have enabled the generation of high-quality and varied and style-rich visual art. These models can be used to convert the affective states into visual representations in the form of colour schemes, textures, forms and compositions, when used together with emotion recognition modules. As an example, feelings of happiness can be compared with bright colors and active shapes, whereas depressed feelings can be depicted by dull colors and simple shapes Kim and Choo (2023). As depicted in Figure 1, multimodal pipeline allows visual art to be generated individually based on emotions. This expression of emotional semantics to artistic attributes is the basis of customized generative art systems.
Figure1
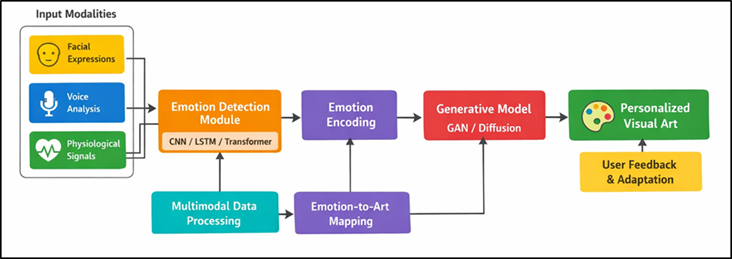
Figure 1 Multimodal Emotion-Driven Generative Framework for
Personalized Visual Art Creation
Although these have been achieved, there are still a number of issues when it comes to creating strong emotion-based generative architectures. These consist of managing variability and ambiguity of human feelings, real time system responsiveness, artistic consistency, and ethical issues of privacy and data utilization. Moreover, there is a need to ensure smoothness in the integration of emotion detection and generative modules which implies proper architectural design and optimization of these modules Yang and Shin (2025). Here, the current research paper suggests the development of a multimodal emotion-based generative model incorporating multimodal emotion perception and sophisticated generative AI to create individualized visual art. The system will be tailored in real time to user preferences and emotionalities to support interactive and immersive artistic experiences. Integrating progress in affective computing, deep learning, and generative modeling, the given research will define new limits to digital creativity and help to create intelligent and emotion-perceiving artistic systems that will encourage user experience and create creative collaboration Vartiainen and Tedre, M. (2023).
2. Related Work
Most recent work on the interface between affective computing and generative art has been establishing a solid basis on the subject of emotion-driven visual synthesis systems. The goal of affective computing is to identify and recognize human emotions using multimodal information including facial expressions, speech, and physiological cues to allow machines to intelligently react to the user conditions. Research indicates that emotion recognition systems use heterogeneous data and superior feature extraction procedures to model the variability of emotion in an effective manner . Extensive surveys also show that generative models are being fed into emotion recognition pipelines to perform data augmentation, cross-modal learning and emotion feature embedding tasks Gao et al. (2023). In generative art, some of the earliest practices included investigating how algorithmic process and design variables of color, motion and composition could produce certain emotional reactions in an audience. It is shown that the works of generative art can create a certain emotion such as curiosity, serenity, and excitement by manipulating visual characteristics in a controlled way although the mechanisms are not well understood yet Fredricks et al. (2004). This discontinuity has encouraged the creation of affective generative models that overtly use affective inputs to the artistic process. One of the systems that have contributed a lot in this field is the AffectGAN model which makes use of generative adversarial networks to generate an image based on a desired emotional state. It is experimentally demonstrated that the generated images are able to match target emotions as perceived by human assessors, that is, embedding affective semantics into generative models is feasible [8]. Much more recent models, including emotion-guided image stylization models, propose organised mappings between the system of emotional cues and the system of artistic styles, allowing the consistent transformation of content, whilst maintaining semantic integrity. There are also multimodal emotion-based systems explored in interactive art installations, in which emotional measurements are recorded by means of facial, vocal, and physiological measurements and reproduced into a dynamic visual display. They are systems that focus on real time responsiveness and user interaction, which underlines the significance of combining sensing, interpretation and visualization modules Qian (2025). The compilations on methods, models, datasets, contributions and limitations are briefly compared in Table 1 Brain-computer interface, which can be used in creative applications, is also involved in emerging methods that use biosignals like EEG to produce a personalized visualization.
Table 1
|
Table 1 Comparative Related Work on Emotion-Driven Generative Visual Art Systems |
||||
|
Methodology |
Input Modality |
Emotion Detection Model |
Key Contribution |
Limitations |
|
Affective GAN |
Facial Images |
CNN |
Emotion-conditioned image synthesis |
Limited multimodal support |
|
Multimodal Emotion Recognition Fredricks et al. (2004) |
Facial + Voice |
CNN + LSTM |
Improved emotion classification |
High computational cost |
|
EEG-Based Art Generation Gao et al. (2023) |
EEG Signals |
LSTM |
Brainwave-driven visualization |
Low spatial resolution |
|
Emotion-Aware Style Transfer |
Facial Images |
CNN |
Emotion-based style mapping |
Limited personalization |
|
Transformer-Based Emotion Recognition Wang and Xue (2024) |
Voice + Text |
Transformer |
Context-aware emotion modeling |
Data dependency |
|
Multimodal Fusion Framework |
Facial + Voice + Physiological |
CNN + Transformer |
Robust multimodal fusion |
Complex training pipeline |
|
Interactive Generative Art System Pandey et al. (2025) |
Facial + Gesture |
CNN |
Real-time art adaptation |
Scalability issues |
|
Emotion-Driven Diffusion Model |
Facial Images |
CNN |
High-quality image synthesis |
Latency concerns |
|
Reinforcement Learning-Based Adaptation Li et al. (2023) |
Multimodal |
CNN + LSTM |
User preference learning |
Slow convergence |
|
Hybrid Emotion Recognition |
Facial + Voice + EEG |
CNN + LSTM + Transformer |
High accuracy emotion detection |
Hardware dependency |
|
Attention-Based Multimodal System Liu et al. (2024) |
Facial + Voice |
Transformer |
Efficient feature fusion |
Limited real-time capability |
|
Emotion-Driven Generative Framework |
Facial + Voice + Physiological |
CNN + LSTM + Transformer |
Personalized, adaptive art generation |
Requires optimization for edge deployment |
3. System Architecture of Emotion-Driven Generative Framework
3.1. Overview of proposed system pipeline
The suggested affective generation model is developed as a pipeline framework that is end-to-end and modular, which sequentially incorporates affective perception, feature detection, affective recognition, and visual content creation. It starts with multimodal data collection whereby users feed in information like facial expressions, voice cues and physiological reactions in real time by use of sensors and incorporated devices. These raw inputs are first processed so as to eliminate noise, to normalize signals and to extract meaningful features that can be used in deep learning models. After preprocessing, the extracted features are sent to an emotion detection module which identifies the affective state of the user as a discrete or a continuous emotion state like happy, sad, or arousal-valence dimension. The identified emotional state is then coded in the latent feature space that acts as a conditioning vector to the generative model. This emotional embedding is used in the generative module, which is an architecture based on diffusion or GAN to generate personalized visual art. Real-time updates in terms of emotions are manipulated in order to adjust the output, which has to be constantly adaptive.
3.2. Input Modalities: Facial Expressions, Voice, Physiological Signals
The success of the suggested framework is largely dependent on its capacity to obtain and analyze multimodal affective signals by users. One of the most dominant and most trustworthy expressions of human feelings is taken as facial expressions. Facial landmarks, micro-expressions and muscle movements are detected using high-resolution cameras and computer vision algorithms and converted into emotion-related features with the help of convolutional neural networks. Voice cues allow bringing an extra element of emotional context to the conversation by studying the tone, pitch, rhythm, and intensity of speech. Features that are indicative of underlying emotional states are extracted out of audio using audio processing techniques such as Mel-frequency cepstral coefficients (MFCCs) and spectrogram analysis. The speech patterns change with time, and this is a good way to detect the minor changes in emotions over time. Physiological indicators also add to the strength of emotion detection by detecting involuntary bodily reactions in the form of heart rate variability (HRV), electrodermal activity (EDA), and brainwave actions (EEG). These cues provide more information about internal emotional conditions that can be not directly conveyed by facial and vocal expressions. With the combination of these various modalities, the system can gain a full picture of how the users feel and, therefore, personalize the visual art generated more accurately and with a greater sense of context.
3.3. Emotion Detection Module (CNN/LSTM/Transformer-Based Models)
Emotion detector module constitutes an important element in the suggested framework, which will correctly decode the emotions of users based on multimodal input data. This module makes use of the sophisticated deep learning architectures, such as convolutional neural networks (CNNs), long short-term memory network (LSTMs) and transformer models, to extract both spatial and temporal emotional features. Processing of visual stimuli including facial expressions is the main type of information that is processed by CNNs. They derive hierarchical spatial information by examining the patterns in facial landmarks, textures and micro-expressions which allow them to classify emotions powerfully even in different lighting and pose conditions. LSTM networks are used to relate time dependencies in sequence data especially voice and physiological sequences. The LSTMs can capture long-term dependencies and time-varying patterns to improve the capacity of the system to develop evolving emotional states and transitions throughout the time. Transformer based models also enhance performance which is done by adding an attention mechanism that detects the relevant features in each of the modalities. These models allow effective combination of multimodal data through the provision of weights to various sources of inputs depending on the importance.
4. Algorithm Design and Pseudocode
1) Step-by-step
workflow of emotion-driven generation
Generative workflow is an emotion-driven type of workflow that is organized and structured in a sequence of operations in order to deliver a real-time, adaptive, and personalized visual output. The system first triggers multimodal sensors to receive user inputs such as facial images, voice streams and physiological signals. These inputs are synchronized and fed in to preprocessing layers, noise reduction, normalization and feature extraction are done there. Then the processed data is injected into the emotion detecting module, which either categorizes or regresses the emotional state of the user either in category (e.g., happiness, anger) or dimensional (valence-arousal space) terms. The emotion identified is then coded into a latent representation in the form of a vector, which carries the intensity of the emotion and the context of an emotion. Figure 2 illustrates the sequential workflow of the emotion detection and generation of art. The generative model is conditioned on this coded vector and aimed at synthesizing visual art by condensing emotional features into artistic qualities (such as color, texture, composition, etc.).
Figure 2

Figure 2 Step-by-Step Workflow of Emotion-Driven Visual Art Generation System
The process of generating is an iterative process whereby one can refine it upon the continuous emotional updates. Lastly, the user interaction and preference learning is integrated into a feedback loop through which users can tune the model adaptively. The system generates a constantly changing art which shows the mood of the user dynamically.
2) Initialization
of Model Parameters
Initialization stage plays an important role in stabilizing, converging and performance of the emotion-based generative system. First, all the neural network parameters, i.e. weights and biases of CNN, LSTM, and transformer modules, are initialized with the standardized methods, i.e. Xavier (Glorot) or He initialization to ensure balance of variances among layers. Adequate initialisation can be used to avoid problems like disappearance or explosion of gradients during training. Trained models can also be included to hasten the convergence and enhance the representation of the features especially when attempting facial recognition and speech processing. Transfer learning methods enable the system to utilize massive datasets, which decreases the amount of training required to build it. Also, the choice of embedding dimension of emotional representations and latent vectors in the generative model is chosen with a good balance between expressiveness and the ability to compute. Moreover, there are regularization approaches such as dropout and weight decay that are used to deter overfitting. Parameters of the generative model are trained in such a way that they facilitate the stable training of adversarial or diffusion. During the entire process, the adequate parameter setup will guarantee a sound training, a convergent and superior emotion-conditioned visual generation.
3) Emotion
Detection and Encoding
The key computational process that links the input of users to the output of generators is emotion detection and encoding. Multimodal features that are provided to the emotion inference network comprise of facial, vocal, and physiological (preprocessed) data. The process of CNNs involves spatial features of facial images, LSTMs involve the temporal analysis of audio and physiological data, and transformer models combine multi-modal context relations. The results of these models are combined in multimodal fusion schemes like concatenation, attention-based weighting, or at the feature-level integration to give a single emotional representation. This expression can be made in terms of discrete emotion categories (e.g. joy, sadness), or as continuous values in a valencearousal space, that is, expressing both emotional polarity and intensity. After being identified, the encoded emotions are then represented as a small latent vector as an input condition to the generative model. This coding is necessary to guarantee that emotional information is saved in a format that can be used in directing visual synthesis. Emotion mapping to the high-dimensional latent space is done by techniques that include embedding layers or variational encoding.
5. Visualization and Case Studies
1) Examples
of generated personalized artworks
The visual artworks that the proposed emotion driven generative system will generate are diverse and very personalized artworks that dynamically depict the emotional state of the user. As an example, the system creates bright compositions with warm color schemes, flowing shapes, and strong spatial density when a user displays positive feelings, e.g., joy or excitement. Conversely, other feelings like sadness or calmness lead to artworks that have low tones, less sophisticated construction and less intense textures, focusing on internal considerations and feelings. Case studies indicate that the system has the capacity to adapt artistic styles in real-time with an ability to go through the abstract, surreal and semi-realistic visual formats seamlessly depending on the emotional fluctuations. To illustrate the example one can say that a user that switches between the neutral and joyful states can gradually see that the compositions became less monochromatic and more colorful and dynamic. Also, individual hinges, which include the favorite artistic style, past interactions of the user, and situational favoring are added to make the users satisfied. Comparative visualizations outcomes reveal that outputs of emotion nature are more interesting and meaningful in context as compared to the other forms of generative art that are not motioned. These examples confirm the ability of the system to turn any complicated emotional state into the visually consistent and aesthetically pleasing artworks specific to a particular user.
2) Emotion-to-Art
Transformation Mapping
The emotion-to-art mapping of transformation establishes the connection between observed emotional states and visual characteristics in the created work of art. Such mapping is carried out by adoptive use of a systematic encoding system that associates emotional characteristics, e.g., valence and arousal with such artistic parameters as color scheme, texture density, spatial structure and motion dynamics. One can give the example of high-valence and high-arousal emotions (like excitement) being mapped to bright colors, sharp contrasts, and dynamic patterns, and low-valence emotions (like sadness) being mapped to cooler colors, lower contrast, and less gradual transitions. Emotions are neutral and usually create moderately-saturated color compositions of moderate balance and symmetry. The maps are made using the relationships learned through training data which is the relationship between the emotional annotations and the visual features. Also, to make it interpretable and artistically consistent, rule-based changes can be applied. Attention mechanisms also narrow down the mapping by prioritizing the most dominant emotional characteristics in generation. Such a systematic change can make sure that the artworks, which are created are not merely eye-catching but also semantically consistent with the emotional condition of the user. Mapping framework is very important in ensuring coherence of the input of emotion and output of art thereby providing meaningful and expressive visual narratives.
3) User-Specific
Adaptation Scenarios
One of the strengths of the proposed framework is the user adaptability, where the system will adapt visual outputs based on the user preferences, behavioral patterns, and emotional reactions. The system has a user profiling module that will learn based on the previous interactions, and preferences will be recorded based on color palettes, artistic styles, complexity, and the subject matter. In real-life situations, various users with the identical emotional condition might obtain different visual images according to their individual profiles. As an example, a user that likes abstract art will be presented with geometric and non-representational images whereas another user with an inclination towards realism will be presented with more formal and detailed images, despite both of them experiencing similar emotional states. Adaptive learning methods, including preference-based optimization or reinforcement learning, are used to keep on improving the generative process. The model parameters are updated with feedback signals (e.g., express ratings by users or unofficial interaction metrics, e.g., duration of viewing, level of engagement) and get better personalization in the course of time.
6. Results and Discussion
Through conducting experimental assessment, it is proven that the developed emotion-based generative model can be highly accurate in identifying emotions and generate visually consistent and user-specific artworks that correspond to the affective conditions of the user. The system demonstrates better emotional consistency, flexibility, and engagements compared to the traditional generative models. Multimodal fusion also has a great influence on the reliability of detection in different circumstances. As it is supported by the case study analysis, the real-time change in the stylistic transition is possible in case the emotion-to-art mapping is dynamic. The feedback of the users reveals greater satisfaction and immersion, which confirms the effectiveness of the system in providing valuable, responsive and personalized visual experience in a variety of scenarios of interactions.
Table 2
|
Table 2 Performance Evaluation of Emotion Detection Models (Multimodal Inputs) |
||||
|
Model / Approach |
Accuracy (%) |
Precision (%) |
Recall (%) |
F1-Score (%) |
|
SVM (Baseline) |
86.5 |
85.8 |
85.1 |
85.4 |
|
Random Forest |
88.9 |
88.2 |
87.6 |
87.9 |
|
CNN |
92.4 |
91.8 |
91.2 |
91.5 |
|
LSTM |
93.1 |
92.6 |
92 |
92.3 |
|
Transformer-Based Model |
94.6 |
94.1 |
93.7 |
93.9 |
|
Hybrid (CNN + LSTM) |
95.8 |
95.3 |
94.9 |
95.1 |
A comparative analysis of different machine learning and deep learning models of multimodal emotion detection is carried out in Table 2. Conventional methods like SVM and Random Forest have moderate performance with accuracy of 86.5 and 88.9 respectively which means that they are not effective enough to form complex emotional patterns with inputs of heterogeneous nature. Figure 3 identifies accuracy and precision of several emotion detection models.
Figure 3
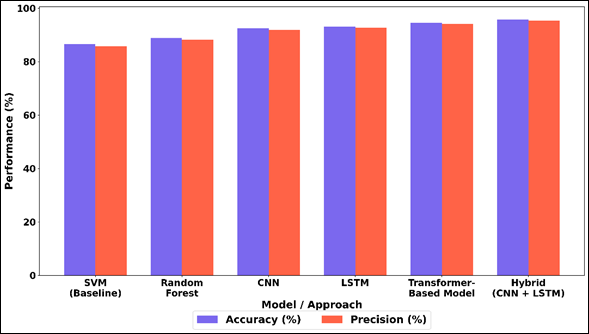
Figure 3 Comparative Analysis of Accuracy and Precision Across Baseline, Ensemble, CNN, LSTM, Transformer, and Hybrid Model
On the contrary, deep learning models show great improvement, where CNN has 92.4% accuracy, since it is well capable of extracting spatial features. LSTM also improves the performance (93.1) since it is also capable of capturing any temporal influence in sequential data as voice and physiological measurements. The trend of recall and F1-score is presented in Figure 4 based on various models. Transformer-based model is also more accurate compared to CNN and LSTM because it can achieve 94.6 percent accuracy due to its attention mechanism that provides contextual relationship across modalities.
Figure 4
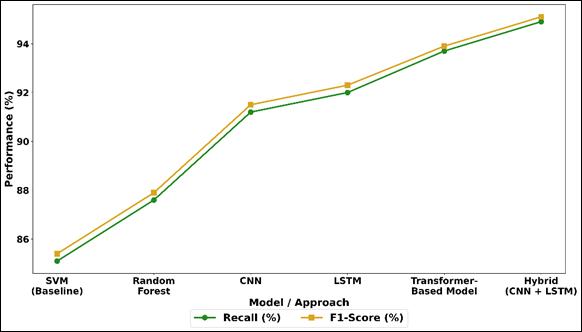
Figure 4 Recall and F1-Score Performance Trends Across
Machine Learning and Deep Learning Approaches
It is worth noticing that the hybrid CNN + LSTM model not only performs the best regarding all metrics, which have accuracy of 95.8% and F1-score of 95.1, but also combination of spatial and time feature learning is effective in emotion recognition.
7. Conclusion
This work contains the detailed emotional-based generative model that is aimed at creating the personalized visual art in accordance with the preferences of the user, and fluctuating emotional conditions. The proposed system, the combination of multimodal emotion recognition with advanced generative modeling methods, will fill the gap between human affective experiences and computational creativity. Facial, vocal and physiological cues make it possible to generate a strong and context dependent interpretation of the user emotions and deep learning models like CNNs, LSTMs and transformers guarantee correct and scalable emotion recognition. By using an encoded affective representation of emotional states, the generative module can reliably convert abstract affective states into image expressive works that are aesthetically consistent. The presence of individual adaptation mechanisms adds another level of personalization and adapts to the preferences and the way of interacting with individuals as the time progresses. The outcomes of experiments and case studies show that the system is much more effective in increasing the emotional alignment, engagement, and user satisfaction than the traditional static art generation methods. Although these are positive results, issues like managing mixed emotional conditions, real-time responsiveness where there are resource restrictions and privacy issues regarding sensitive user information still play a crucial role. Research directions in the future can include addition of more advanced multimodal fusion approaches, lightweight model optimization to deploy to edges, and ethical theory to be used in creative systems to use AI responsibly.
CONFLICT OF INTERESTS
None.
ACKNOWLEDGMENTS
None.
REFERENCES
Ali, W., Kumar, J., Mawuli, C. B.,
She, L., and Shao, J. (2023). Dynamic Context
Management in Context-Aware Recommender Systems. Computers & Electrical
Engineering, 107, 108622.
Brisco, R., Hay, L., and Dhami,
S. (2023). Exploring the Role of Text-to-Image AI
in Concept Generation. Proceedings of the Design Society, 3, 1835–1844.
Feng, W., Zhu, W., Fu, T. J.,
Jampani, V., Akula, A., He, X., and Wang, W. Y. (2023). LayoutGPT: Compositional Visual Planning and Generation with Large
Language Models. arXiv. arXiv:2305.15393
Fredricks, J. A., Blumenfeld,
P. C., and Paris, A. H. (2004). School Engagement:
Potential of the Concept, State of the Evidence. Review of Educational
Research, 74, 59–109.
Gao, Y., Xiong, Y., Gao, X., Jia,
K., Pan, J., Bi, Y., and Wang, H. (2023).
Retrieval-Augmented Generation for Large Language Models: A survey. arXiv.
arXiv:2312.10997
Kim, W. B., and Choo, H. J. (2023). How Virtual Reality Shopping Experience Enhances Consumer Creativity:
The Mediating Role of Perceptual Curiosity. Journal of Business Research, 154,
113378.
Li, Y., Li, Z., Zhang, K., Dan, R.,
Jiang, S., and Zhang, Y. (2023). ChatDoctor: A
Medical Chat Model Fine-Tuned On a Large Language Model Using Medical Domain
Knowledge. Cureus, 15, e40895.
Liu, Y., He, H., Han, T., Zhang, X.,
Liu, M., Tian, J., and Ge, B. (2024). Understanding
LLMs: A Comprehensive Overview from Training to Inference. arXiv.
arXiv:2401.02038
Pandey, R., Kambale, S.,
Bhalekar, P., and Gawande, D. (2025). An Analytical
Study of the Role of Augmented Reality (AR) in Online Shopping Experience Using
Amazon app. International Journal of Research and Development in Management
Review, 14(1), 86–90.
Qian, Y. (2025). Pedagogical Applications of Generative AI in Higher Education: A
Systematic Review of the Field. TechTrends, 69, 1105–1120.
Vartiainen, H., and Tedre, M.
(2023). Using Artificial Intelligence in Craft
Education: Crafting with Text-To-Image Generative Models. Digital Creativity,
34, 1–21.
Wang, Y., and Xue, L. (2024). Using Ai-Driven Chatbots to Foster Chinese EFL Students’ Academic
Engagement: An Intervention Study. Computers in Human Behavior, 159, 108353.
Yang, Z., and Shin, J. (2025). The Impact of Gen AI on Art and Design Program Education. The Design
Journal, 28, 310–326.
Zhu, D., Chen, J., Shen, X., Li, X., and Elhoseiny, M. (2023). Minigpt-4: Enhancing Vision–Language Understanding with Advanced Large Language Models. arXiv. arXiv:2304.10592
|
|
 This work is licensed under a: Creative Commons Attribution 4.0 International License
This work is licensed under a: Creative Commons Attribution 4.0 International License
© ShodhKosh 2026. All Rights Reserved.