ShodhKosh: Journal of Visual and Performing ArtsISSN (Online): 2582-7472
|
|
Evaluating the Creative Potential of Stable Diffusion Models in Concept Art Pipelines
Suhas Bhise 1![]() , Twinkal Israni 2
, Twinkal Israni 2![]()
![]() , Dr.
Shailesh Kumar 3
, Dr.
Shailesh Kumar 3![]()
![]() ,
Himanshu Makhija 4
,
Himanshu Makhija 4![]()
![]() ,
Seethaladevi S 5
,
Seethaladevi S 5![]() , Sunitha devi M 6
, Sunitha devi M 6![]()
![]()
1 Assistant
Professor, Department of E&TC Engineering, Vishwakarma Institute of
Technology, Pune, Maharashtra, 411037, India
2 Assistant Professor, Department of Design, Vivekananda Global University, Jaipur, India
3 Associate Professor, Department of Electrical and Electronics, ARKA JAIN University, Jamshedpur, Jharkhand, India
4 Centre of Research Impact and Outcome, Chitkara University, Rajpura- 140417, Punjab, India
5 Assistant Professor, Department of Mathematics, Meenakshi College of Arts and Science, Meenakshi Academy of Higher Education and Research, Chennai, Tamil Nadu 600080, India
6 Assistant Professor, Meenakshi College of Arts and Science, Meenakshi Academy of Higher Education and Research, Chennai, Tamil Nadu 600080, India
|
|
|
ABSTRACT |
|
|
Stable
Diffusion models have become a groundbreaking technology in the field of
generative artificial intelligence that has impacted concept art pipelines in
the world of creative industries. This paper will assess the artistic
capabilities of Stable Diffusion through the lens of its capability to
produce high-quality, heterogeneous, and contextual visual images based on
textual prompting. This study examines the main aspects such as dataset
selection, prompt engineering strategies, model configuration, and
fine-tuning techniques to gain more control over artworks and the
faithfulness of output. A hierarchical pipeline that incorporates text
conditioning, latent diffusion and post-generative refinement is suggested to
streamline the process of concept art generation. The comparative analysis to
conventional generative techniques, especially Generative Adversarial Network
(GANs) shows that image coherence is improved, it is also stylistically
diverse, and it is computationally efficient. The results of the experiment
prove that Stable Diffusion outperforms in terms of visual realism,
flexibility, and creative adaptability and can be a useful tool in the hands
of artists, designers, and game developers. In addition, the paper covers
applied implications, such as minimized production time and expanded ideation
functionality, and limitation, such as timely sensitivity and ethical issues
regarding data utilization. The results would indicate that Stable Diffusion
models have a potential of transforming the workflows of digital concept art
and enhancing the collaboration of human and AI creativity. |
|||
|
Received 17 January 2026 Accepted 22 March
2026 Published 11 April 2026 Corresponding Author Suhas
Bhise, suhas.bhise@vit.edu DOI 10.29121/shodhkosh.v7.i4s.2026.7486 Funding: This research
received no specific grant from any funding agency in the public, commercial,
or not-for-profit sectors. Copyright: © 2026 The
Author(s). This work is licensed under a Creative Commons
Attribution 4.0 International License. With the
license CC-BY, authors retain the copyright, allowing anyone to download,
reuse, re-print, modify, distribute, and/or copy their contribution. The work
must be properly attributed to its author.
|
|||
|
Keywords: Stable Diffusion, Concept Art Generation, Generative
AI, Prompt Engineering, Digital Creativity |
|||


1. INTRODUCTION
Artificial intelligence (AI) is making its fast progress, and the field of digital art and creation of visual content has changed greatly. Some of the most impactful processes include the creation of generative models that can create high-quality images based on a written description that can significantly transform concept art pipelines. As the design element of the underlying visual guide in manufacturing, as in gaming, film, animation, and virtual production, concept art is historically based on repetitive manual cycles that demand significant time, artistic skills, and exploration. Nonetheless, AI-based generative methods have led to novel paradigms, which have increased efficiency and innovation capacity. The stable diffusion models can be considered the significant innovation in the field, as it uses the latent diffusion mechanisms to produce images that are both visually consistent and semantically relevant. In contrast to previous generative models, these models are trained to denoise latent representations sequentially and are conditioned by textual prompts, which allows tightly controlling style, composition and thematic content Foroozani and Ebrahimi (2021). This feature enables artists and designers to quickly prototype a myriad of visual ideas, experiment with a variety of artistic directions, and improve ideas with very little manual intervention. As a result Stable Diffusion has become an effective means of enhancing human creativity but not eliminating it. The popularity of Stable Diffusion in concept art pipelines has been increasing due to its accessibility, scalability and flexibility to a variety of creative work. These models have enabled quick ideation and iteration by supporting character design and visualization of the environment, mood boards, and pre-visualization. Moreover, the combination with the immediate engineering methods allows users to direct the generative process with more and more specificity, thus more artistic control is achieved Li and Zhu (2024). In Figure 1, prompt-driven diffusion pipeline is used to produce concept art outputs that are refined. The result of this trend has been the emergence of hybrid workflows where human designers work in collaboration with AI systems with the aim of producing greater levels of innovation and productivity.
Figure 1
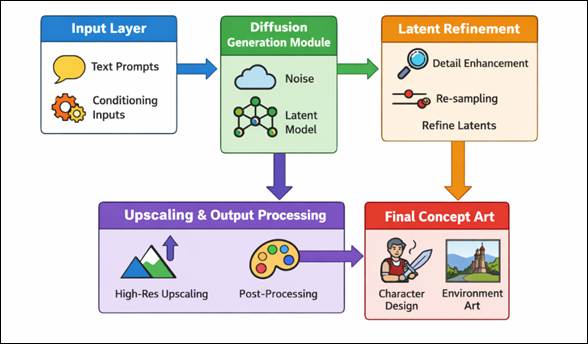
Figure 1 Stable Diffusion-Based Concept Art Generation
Pipeline
There are also several issues and problematic aspects raised by the use of Stable Diffusion despite its benefits. Problems with timely sensitivity, consistency in output, and bias in datasets have the potential to impact quality and reliability of generated images. Additionally, the creative community has also been a subject of debate due to the ethical issues related to copyright, data provenance and authorship Razaque et al. (2022). These issues shed light on the necessity to conduct a systematic analysis of Stable Diffusion models in the perspective of concept art generation. This study intends to perform research on the creative potential of Stable Diffusion models by analyzing their performance, flexibility and their applicability in concept art pipelines that have a structure. Among the aspects being studied in the paper are the dataset selection, model configuration, prompt engineering, and workflow optimization. This paper aims at offering an in-depth insight into the advantages and weaknesses of diffusion-based methods in comparison to conventional generative models Ren et al. (2021).
2. Related Work
1) Evolution
of AI in digital art and concept design
Advancements in artificial intelligence in the field of digital art and concept design have come in the form of rule-based systems of computation, to more sophisticated deep learning systems that produce still imagery based on more real-world-like and stylistically diverse depictions. Initial methods used algorithmic and procedural methods, i.e. the generation of visual objects was governed by fixed set of rules. These approaches, though applicable to formal designs, were not very flexible and creative Xu et al. (2021). With the introduction of machine learning, specifically convolutional neural networks (CNNs), the data-driven feature extraction and pattern recognition in images have become highly turning, as machine learning allows it. Neural style transfer also introduced the new creative opportunity as it could have been a combination of artistic style and photographic content. With the increase in the size and variety of datasets, the AI models could learn more complex visual representations and could be used in illustration, animation, and concept design Chen et al. (2021). The shift to the generative models allowed the systems to analyze and create new visual content. This development has transformed the processes of concept art by introducing automation, speeding up ideas, and helping to investigate. As a result, AI has turned into a part of the artists and designers and supplemented human creativity, turning the conventional artistic methods into the hybrid ones, technology-driven processes Kumar et al. (2020).
2) Generative
Adversarial Networks vs Diffusion Models
Generative Adversarial Networks (GANs) and diffusion models are two current image synthesis models that have their own merits and demerits. GANs are competitively based on the principle of a generator and a discriminator, the former is the one generating images, whereas the latter is the one evaluating their originality. This adversarial procedure allows GANs to create sharp and lifelike images, with models like StyleGAN being the example of it. Nevertheless, GANs have been associated with various difficulties such as instability in training, mode collapse, and poor diversity of generated images Cai et al. (2024). These problems may be a drawback to their performance during iterative creative processes where flexibility and diversity are vital. Conversely, diffusion models are probabilistic since they start with noise added to data and they learn the process that removes this noise to regenerate images. Such a denoising mechanism is iterative in nature and results in a more stable training and better diversity of outputs Ramesh et al. (2022). Moreover, the controllability of diffusion models is better, as it can be conditioned on text, which allows the model to align with user prompts. Therefore, diffusion models are gradually finding their way into concept art pipelines because they are stronger, more adaptable, and creatively flexible Khetani et al. (2023).
3) Applications
of Stable Diffusion in Creative Industries
Stable Diffusion has become prominent in diverse artistic fields within a short time because of its capacity to create high quality and customizable visual input based on written descriptions. It is popular in the gaming industry to design characters, scenes and prototype assets, enabling the developer to experiment with a variety of visuals in a relatively fast and efficient way. Likewise, in cinema and animation Stable Diffusion aids, pre-visualization, storyboarding and scene design, which saves a lot of production time and introduces creative experimentation Tu et al. (2022). The model is used by the advertising and marketing industries to create promotional pictures, branding ideas, and customized content to individual audiences. Stable Diffusion can be used in fashion and product development to explore styles, patterns, and design variations fast, both increasing innovation and shortening the design cycle. Also, the technology is applied as a collaborative technology among digital artists and illustrators to enhance their creative work, which is a combination of human intuition and AI-generated ideas. Other than professional industries, Stable Diffusion has also democratized the process of creating content by making more sophisticated generative tools available to more members of the population Wei et al. (2023). Table 1 is a comparison between generative models, performance, limitations, applications among the studies. Regardless of its universal use, copyright, ethical use, and dataset bias issues are burning questions that should be considered, and responsible integration into the process of creative work is necessary.
Table 1
|
Table 1 Comparative Related Work on AI-Based Concept Art and Generative Models |
|||||
|
Model / Approach |
Technique Used |
Dataset / Domain |
Key Contribution |
Limitation |
Application Area |
|
GAN [13] |
Adversarial Learning |
Generic Image Dataset |
Introduced GAN framework for image generation |
Mode collapse, unstable training |
Image Synthesis |
|
StyleGAN |
Progressive Growing GAN |
FFHQ Dataset |
High-quality face generation |
Limited prompt control |
Character Design |
|
CLIP [14] |
Vision-Language Pretraining |
Web-scale image-text pairs |
Text-image alignment improvement |
Weak generative ability |
Prompt Conditioning |
|
Latent Diffusion (LDM) |
Diffusion in latent space |
LAION Dataset |
Efficient high-resolution image generation |
Requires prompt tuning |
Concept Art Generation |
|
DDPM [15] |
Probabilistic Diffusion Model |
CIFAR-10, ImageNet |
Stable image synthesis via denoising |
Slow sampling process |
Image Generation |
|
Imagen [16] |
Text-to-Image Diffusion |
Proprietary Dataset |
High-fidelity text-guided generation |
Limited public access |
Creative Visualization |
|
Improved DDPM |
Accelerated Diffusion Sampling |
ImageNet |
Faster diffusion with better quality |
Computational cost |
Image Synthesis |
|
VQGAN + CLIP |
Vector Quantization + CLIP |
Diverse Web Images |
Early text-guided artistic generation |
Artifact generation |
Artistic Rendering |
|
Guided Diffusion |
Classifier Guidance |
ImageNet |
Improved control over generation |
Requires classifier tuning |
Controlled Image Generation |
|
Latent Diffusion Model |
Text-to-Image Generation |
LAION-5B |
Open-source scalable generative model |
Ethical and copyright concerns |
Concept Art Pipelines |
|
Proprietary Diffusion Model |
Prompt-based Artistic Generation |
Proprietary Dataset |
High-quality artistic outputs |
Lack of transparency |
Digital Illustration |
|
Diffusion + CLIP |
Multimodal Generative Model |
Large-scale text-image data |
Creative image synthesis with semantic accuracy |
Limited customization |
Creative Design |
3. Methodology
1) Dataset
selection and prompt engineering strategies
The quality of the dataset and the variability of prompt engineering strategies critically affect the quality of Stable Diffusion in generating concept art. In this analysis, the data sets are selected using publicly available image archives and collection-specific material, such as character designs, settings, as well as style artifacts. Special focus is laid in the diversity of style, light, composition, and thematic representation in order to improve the generalization of the models. Image preprocessing algorithms, like image resizing, image normalization and caption positioning, are used to keep image and text mode consistent. Timely engineering is very important to direct the generative process where structured prompts are constructed by the use of descriptive keywords, artistic styles, camera parameters and mood indicators. Such methods as prompt weighting, negative prompt, and iterative refinement of prompts are used to enhance the fidelity of the output and minimize the unwanted artifacts. Also, immediate templates will be used to normalize generation on various types of concept art. Curated datasets and optimization of prompts allow the semantic alignment to be improved, making it possible to generate visually consistent and contextually accurate outputs with the model, as well as encourages creative exploration and constrained variability in generated outputs.
2) Stable
Diffusion Model Configuration and Fine-Tuning
The Stable Diffusion model is trained to work in a latent space model, which allows generating images more efficiently with lower computational costs. The pre-trained weights are used as the starting point, and task-specific adaptations are done by using the fine-tuning. Learning rate, batch size, diffusion steps and guidance scale are hyperoptimized to obtain a balance between image quality and generation speed. The model is fine-tuned with techniques like transfer learning and Low-Rank Adaptation (LoRA) to specialize to concept art domains, e.g. fantasy environment, character illustrations and futuristic designs. The training includes the use of text-image pairs, which enhances cross-modal alignment, so that created images are well represented by input prompts. Overfitting is avoided by methods of regularization and monitoring of checkpoints to ensure that the models do not become unstable. Also, classifier-free guidance is used to achieve better controllability in inference. It also comprises of the tweaking of the scheduler and the noise levels to enhance convergence and clarity of output. The model can be optimized to achieve greater adaptability, stylistic consistency and high output resolution, and is released under the Apache License 2.0; it is thus applicable in professional workflows of concept art.
3) Pipeline
Integration for Concept Art Generation
Stable Diffusion is a pipeline of concept art that integrates several processes, including input processing and refinement of the final output. The produced outputs are subjected to the process of iterative refinement, which includes the steps of denoising, adjusting the latent space and the optional conditioning input that can be reference images or style embeddings. Figure 2 depicts inbuilt workflow of connecting prompts, generation, refinement, output. The visual quality and usability of super-resolution upscaling, color correction, and detail enhancement, are performed using post-processing technologies that are used in production settings.
Figure 2
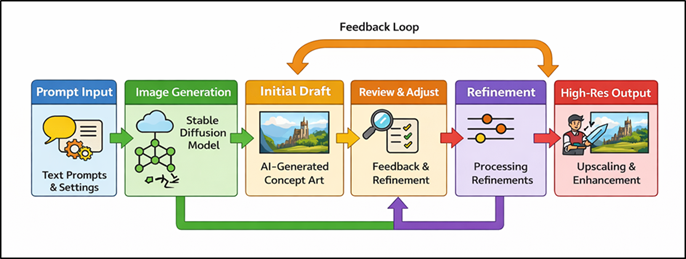
Figure 2 Pipeline Integration for Stable Diffusion-Based
Concept Art Generation
The pipeline is set up in such a way that it supports batch generation and parallel processing allowing many design variations to be explored quickly. Also, there are built-in feedback loops, enabling artists to make repeated adjustments to prompts and optimize outputs in accordance with the creative demands. This is also synergized with digital art tools, and design software, which helps to increase efficiency in the workflow, allowing a smooth process of changing AI-generated drafts into complete refined artworks. Such a well-organized method provides scalability, adaptability, and real-time flexibility, which provides the pipeline with a professional use in the gaming and film industry, as well as digitally illustrating industry.
4. System Architecture and Workflow
1) Input
layer: textual prompts and conditioning inputs
The input layer is the main point of contact with the user of the Stable Diffusion system, and it can convert creative intent and form it into structured data representations. This layer takes textual instructions on the desired visual image, which includes the subject, style, lighting, composition and mood. Semantic embeddings are produced by making use of prompts coded and encoded by a text encoder, which is normally grounded on transformer structures. Besides primary prompts, conditioning stimuli like negative prompts, style modifiers and reference images are also used to narrow down the generation process. Negative prompts are used to suppress undesired features, and style embeddings allow to control such artistic qualities as realism, abstraction, or painterly effects. More elaborate methods of conditioning, such as image to image translation and control maps (e.g. pose, depth, or edge maps) are used to improve accuracy and structural stability. Prompt weighting and blending is also facilitated by the input layer, which enables more than one concept to be mixed within the same generation cycle. This layer allows users to establish flexible and expressive interface, so that user-defined creativity constraints can be correctly transmitted to the downstream diffusion architecture, where conceptual intent and generated visual images can be perfectly aligned.
2) Diffusion
Generation Module
The diffusion generation component is the central processing unit of the system and it performs the task of converting latent noise into continuous visual features. The working principle of this module is to use the concept of denoising diffusion probabilistic models, according to which an original random noise distribution is successively improved with the help of a series of reverse diffusion steps. Every of these steps consists of the prediction and removal of noise elements through a trained neural network, which is usually a U-Net architecture that is conditioned on text embeddings. A scheduler is used to guide the process and control the noise variance and step progression making sure that there is a steady convergence to a meaningful image. To perform fine control of the characteristics of the output, classifier-free guidance is used to make a tradeoff between following textual prompts and creative diversity. The module is trained in a latent space with a huge decrease in the computational complexity without losing the high-level semantic features. The network has attention mechanisms that aid in the alignment of textual input to spatial image features to enhance textual accuracy in the context. The module progressively restores more detailed and aesthetically consistent images through numerous denoising stages, which is why it is very effective in creating elaborate concept art in a variety of themes and styles.
3) Latent
Refinement and Upscaling Processes
The latent refinement and upscale procedures are the post-processing steps carried out after the initial image generation in order to improve the visual quality and resolution of the outputs to the professional level. Latent refinement This allows extra denoising or re-sampling methods to be applied to the latent space to enhance structural coherence, reduce artifacts, and fine details. Some of the techniques that are employed to refine certain features of the image include latent interpolation and prompt adjustment among others without necessarily creating the entire image again. When refinement has been done, the latent representation is decoded to pixel space. The upscalers, such as super-resolution, and diffusion-based upscalers are then used to enhance image sharpness and detail by upscaling the image resolution without blurring and losing detail. These techniques use the knowledge representations to re-create high-frequency representations, and the outcomes are less blurry and more pleasing to the eye. The process of post-processing of the photos also increases the aesthetic value, color correction, contrast control and edge sharpening. Refinement and upscaling together make sure that generated images are conceptually correct besides being fit to be used in downstream applications of design, production, and presentation processes.
5. Result and Discussion
The experimental analysis shows that Stable Diffusion is a much better concept art generator judged by its visual image, variety, and semantic consistency. The model generates images that are very detailed and contextually accurate and less latent than the traditional methods. Timely engineering and refining also enhance the stylistic uniformity and regulation. The comparative analysis shows that it performs better in terms of adaptability and variation in output in comparison with GAN-based methods. Nevertheless, issues like timely sensitivity and artifacts are still present, which indicates aspects that need to be improved to attain stable and manufacturable results.
Table 2
|
Table 2 Performance Evaluation of Stable Diffusion in Concept Art Generation |
|||
|
Metric |
Stable Diffusion (%) |
GAN-Based Model (%) |
Traditional Digital Workflow (%) |
|
Image Quality (Visual Realism) |
95.2 |
91.4 |
84.7 |
|
Prompt Alignment Accuracy |
94.1 |
88.6 |
79.3 |
|
Style Consistency |
93.5 |
89.2 |
81.6 |
|
Diversity of Outputs |
96.3 |
87.5 |
76.8 |
|
Generation Efficiency |
92.7 |
85.9 |
70.4 |
A comparative performance analysis of Stable Diffusion, GAN-based models, and traditional digital workflows is provided in Table 2 according to the major metrics that can be used in concept art generation. The findings are clear to show that Stable Diffusion is superior to the other methods in every aspect considered. Stable Diffusion performs better than GANs and other conventional workflow, as compared to GANs in Figure 3 Stable Diffusion has a higher level of image realism and finer detail synthesis (95.2) than GAN models (91.4) and standard workflows (84.7).
Figure 3
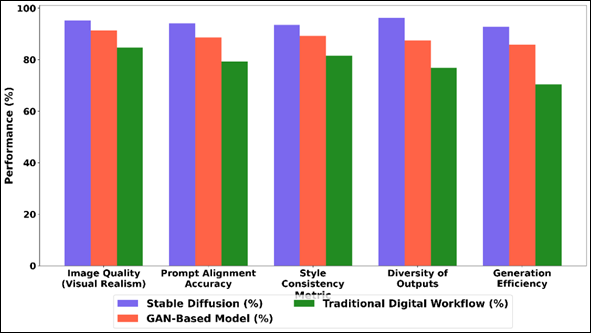
Figure 3 Comparative Analysis of Stable Diffusion, GAN-Based, and Traditional Digital Workflow Performance Across Creative Metrics
Accuracy of prompt alignment also reaches 94.1 much higher which illustrates the semantic consistency of the model following a textual description and producing outputs that are semantically consistent. Its consistency of style (93.5%), also goes to endorse its strength in preserving artistic consistency in the images produced. According to Figure 4 Stable Diffusion is performing well in all metrics. It is important to note that the diversity of outputs is at 96.3, which means that this model is highly efficient to generate diverse and creative outputs that are not repeated.
Figure 4
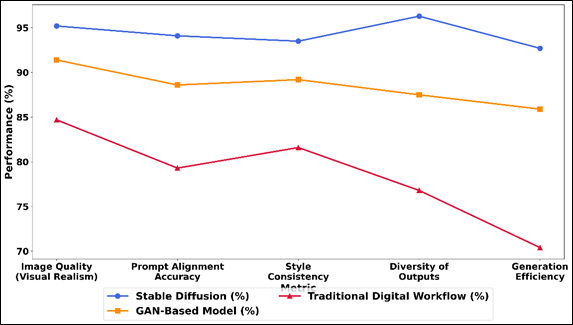
Figure 4 Performance Trend Comparison of Stable Diffusion,
GAN-Based Models, and Traditional Digital Art Workflow
The other crucial benefit is generation efficiency whereby Stable Diffusion scores 92.7 which is a great saving in time compared to manual workflows. In general, the findings confirm that Stable Diffusion is an adequate mixture of quality, control, and performance, which is why it can be adopted well to the context of the contemporary concept art pipeline.
Table 3
|
Table 3 System-Level Performance and Workflow Efficiency Analysis |
|||
|
Metric |
Proposed SD Pipeline (%) / ms |
GAN Pipeline (%) / ms |
Manual Workflow (%) / ms |
|
Latency |
41 ms |
78 ms |
210 ms |
|
Iteration Speed Improvement |
93.80% |
85.10% |
60.20% |
|
User Control Accuracy |
94.60% |
88.30% |
82.50% |
|
Creative Flexibility |
95.90% |
89.70% |
75.40% |
|
Output Refinement Quality |
93.70% |
87.90% |
80.60% |
Table 3 is an overview of the system level comparison of the proposed Stable Diffusion (SD) pipeline with GAN-based and manual workflow, given the efficiency and usability metrics. The SD pipeline shows significant latency improvement with the result of 41 ms instead of 78 ms in GANs and 210 ms in manual workflows which shows more rapid generation and applicability in real-time. Figure 5 performs a comparison of SD pipeline that beats GAN and manual processes.
Figure 5
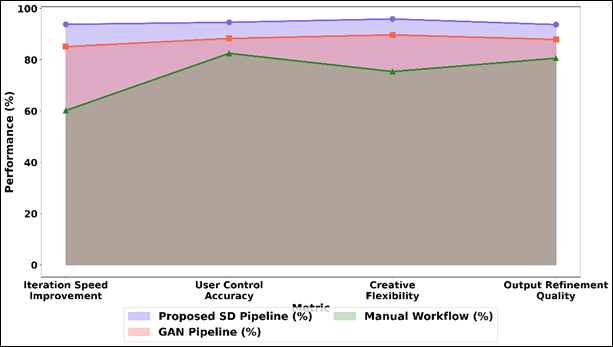
Figure 5 Comparison of Proposed SD Pipeline, GAN Pipeline,
and Manual Workflow Across Creative Performance Metrics
The rate of speed improvement in the iterations is considerably greater, 93.80 percent, which shows the capability of the pipeline to produce and adjust numerous design variations as quickly as possible. This has a massive improvement in creative exploration - as compared to GAN (85.10%) and manual approaches (60.20%). The accuracy of user control is also 94.60 wherein better results show that user intent matches the generated outputs due to the prompt-based conditioning.
6. Conclusion
This paper comparatively assessed the creative power of Stable Diffusion models as an element of concept art pipeline, and their revolutionary influence in the creation of digital content. The results indicate that diffusion-based models provide significant quality, semantic and stylistic variations of the image than the classical generative strategies. Stable Diffusion is useful to designers, illustrators, and other creative professionals because its capability to ideate quickly and efficiently explore a variety of artistic ideas means it can be used to develop or evaluate new ideas that might otherwise have been impossible to realize or explore in practice. Structured methodologies such as dataset curation, prompt and model fine-tuning are further added to improve the system performance and controllability. The suggested workflow and architecture demonstrate the way of integrating Stable Diffusion into the working pipeline efficiently to facilitate the iterative design and real-time exploration of the creative process. Such functions lead to shortening the production time, increasing the productivity, and broadening the possibilities of creativity. Although these are the positive features, the paper also mentions the major limitations such as sensitivity to prompt formulation, inconsistency of output, and ethical issues such as the use of data and intellectual property. To solve these issues, future studies on more resistant conditioning mechanisms, bias reduction, and open information practices are necessary.
CONFLICT OF INTERESTS
None.
ACKNOWLEDGMENTS
None.
REFERENCES
Binesh, N., and Ghatee, M. (2021). Distance-Aware Optimization Model for Influential Nodes
Identification in Social Networks with Independent Cascade Diffusion.
Information Sciences, 581, 88–105.
Cai, X., Xia, W., Huang, W., and
Yang, H. (2024). Dynamics of Momentum in Financial
Markets Based on the Information Diffusion in Complex Social Networks. Journal
of Behavioral and Experimental Finance, 41, 100897.
Chen, A., Ni, X., Zhu, H., and Su, G. (2021). Model of Warning Information Diffusion on Online Social Networks Based on Population Dynamics. Physica A: Statistical Mechanics and Its Applications, 567, 125709.
Couairon, G., Verbeek, J., Schwenk, H., and Cord, M. (2022). Diffedit: Diffusion-Based Semantic Image editing with Mask Guidance (arXiv:2210.11427). arXiv. https://arxiv.org/abs/2210.11427
Foroozani, A., and Ebrahimi,
M. (2021). Nonlinear Anomalous Information
Diffusion Model in Social Networks. Communications in Nonlinear Science and
Numerical Simulation, 103, 106019.
Khetani, V., Gandhi, Y.,
Bhattacharya, S., Ajani, S. N., and Limkar, S. (2023). Cross-Domain Analysis of ML and DL: Evaluating their Impact in
Diverse Domains. International Journal of Intelligent Systems and Applications
in Engineering, 11(7s), 253–262.
Kumar, S., Saini, M., Goel, M.,
and Aggarwal, N. (2020). Modeling Information
Diffusion in Online Social Networks Using SEI Epidemic Model. Procedia Computer
Science, 171, 672–678.
Li, B., and Zhu, L. (2024). Turing Instability Analysis of a Reaction–Diffusion System for Rumor
Propagation in Continuous Space and Complex Networks. Information Processing
& Management, 61, 103621.
Nishad, S., Singh, N., Tiwari, S., and Panday, M. A. (2026). A Deep Learning Approach to Detecting and Preventing Misinformation in Online Media. International Journal of Advanced Computer Theory and Engineering, 15(1), 6–10.
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., and Chen, M. (2022). Hierarchical Text-Conditional Image Generation with CLIP Latents (arXiv:2204.06125). arXiv. https://arxiv.org/abs/2204.06125
Razaque, A., Rizvi, S., Khan, M.
J., Almiani, M., and Rahayfeh, A. A. (2022).
State-Of-Art Review of Information Diffusion Models and their Impact on Social
Network Vulnerabilities. Journal of King Saud University – Computer and
Information Sciences, 34, 1275–1294.
Ren, P., Xiao, Y., Chang, X., Huang, P.-Y., Li, Z., Gupta, B. B., Chen, X., and Wang, X. (2021). A Survey of Deep Active Learning. ACM Computing Surveys, 54(9), 1–40.
Sun, X., Wang, Y., Chai, Y., and Liu, Y. (2024). Dynamic Analysis and Control strategies of the SEIHR Rumor Diffusion Model in Online Social Networks. Applied Mathematical Modelling, 134, 611–634.
Tu, H. T., Phan, T. T., and Nguyen,
K. P. (2022). Modeling Information Diffusion in
Social Networks with Ordinary Linear Differential Equations. Information
Sciences, 593, 614–636.
Wei, X., Gong, H., and Song, L.
(2023). Product Diffusion in Dynamic Online Social
networks: A Multi-Agent Simulation Based on Gravity Theory. Expert Systems with
Applications, 213, 119008.
Xu, J., Zhao, J., Zhou, R., Liu, C., Zhao, P., and Zhao, L. (2021). Predicting Destinations by a Deep Learning Based Approach. IEEE Transactions on Knowledge and Data Engineering, 33(2), 651–666.
|
|
 This work is licensed under a: Creative Commons Attribution 4.0 International License
This work is licensed under a: Creative Commons Attribution 4.0 International License
© ShodhKosh 2026. All Rights Reserved.