ShodhKosh: Journal of Visual and Performing ArtsISSN (Online): 2582-7472
|
|
Computational Pattern Recognition for Identifying Cultural Symbolism in Regional Art Forms
Jyotsna Suryavanshi 1![]() , Nivetha N. 2
, Nivetha N. 2![]() , Dr. Kajal Thakuriya 3
, Dr. Kajal Thakuriya 3![]()
![]() ,
Dr. Irphan Ali 4
,
Dr. Irphan Ali 4![]()
![]() ,
Dikshit Sharma 5
,
Dikshit Sharma 5![]()
![]() ,
Mahendihasan S. Heera 6
,
Mahendihasan S. Heera 6![]()
![]() , Muninathan N. 7
, Muninathan N. 7![]()
1 Department of Engineering, Science and
Humanities, Vishwakarma Institute of Technology, Pune, Maharashtra, 411037,
India
2 Assistant Professor, Computer Science,
Meenakshi College of Arts and Science, Meenakshi Academy of Higher Education
and Research, Chennai, Tamil Nadu 600080, India
3 HOD, Professor, Department of Design, Vivekananda Global
University, Jaipur, India
4 Associate Professor, Department of Computer Science and Engineering
(CSBS), Noida Institute of Engineering and Technology, Greater Noida, Uttar
Pradesh, India
5 Centre of Research Impact and Outcome, Chitkara University, Rajpura-
140417, Punjab, India
6 Assistant Professor, Faculty of Computer Science and Application, Gokul Global University, Sidhpur, Gujarat, India
7 Scientist, Central Research Laboratory, Meenakshi College of Arts
and Science, Meenakshi Academy of Higher Education and Research, Chennai, Tamil
Nadu 600080, India
|
|
|
ABSTRACT |
|
|
Regional art
forms have a rich cultural symbolism that defines the beliefs, identities and
traditions of various communities. Nevertheless, these symbolic elements are
usually interpreted subjectively, in an intensive and expensive way, and
restricted by the number of domain experts. In this paper, a proposal has
been made on a computational design to recognize the cultural symbolism of
regional art through advanced pattern recognition and recognition algorithms.
The strategy incorporates the elements of image processing, feature
extraction, deep learning, and cultural knowledge modeling to allow the
analysis of artistic patterns that are automated and context-dependent. The
framework uses preprocessing and segmentation in isolating valuable visual
attributes and then uses feature extraction techniques to capture color,
texture and shape attributes. A hybrid deep learning model based on
Convolutional Neural Networks (CNNs) and attention is applied to acquire both
the local and global representations of symbolic patterns. Additionally, a
cultural knowledge base is also added to annotate the patterns that are
identified to their semantic meanings to help to read between the lines
better. The experimental outcomes prove that the suggested model performs on
a high level and the level of accuracy reaches over 90 percent, the
stabilities of precision and recall between different symbol categories are
relatively high, as well. The comparative analysis with the baseline models
shows the excellence of the proposed method in identification of multifarious
and multifaceted symbolic elements. Attention visualization as the form of
the explainable outputs of the system makes it applicable to the cultural
heritage preservation, digital museums, and to the AI-aided interpretation of
art. |
|||
|
Received 18 January 2026 Accepted 05 March
2026 Published 11 April 2026 Corresponding Author Jyotsna
Suryavanshi, jyotsna.suryavanshi@vit.edu DOI 10.29121/shodhkosh.v7.i4s.2026.7478 Funding: This research
received no specific grant from any funding agency in the public, commercial,
or not-for-profit sectors. Copyright: © 2026 The
Author(s). This work is licensed under a Creative Commons
Attribution 4.0 International License. With the
license CC-BY, authors retain the copyright, allowing anyone to download,
reuse, re-print, modify, distribute, and/or copy their contribution. The work
must be properly attributed to its author.
|
|||
|
Keywords: Computational Pattern Recognition, Cultural
Symbolism, Regional Art, Deep Learning, Convolutional Neural Networks,
Feature Extraction, Multimodal Learning, Cultural Heritage Preservation,
Explainable AI |
|||


1. INTRODUCTION
The regional art forms are a rich heritage of cultural identity reflecting centuries of tradition, belief systems and social narratives. In the complex tribal images and folk paintings to the classical patterns of decoration, these artistic manifestations act as aesthetic artifacts, as well as symbolic storage of cultural knowledge. Such artworks have cultural symbolism, which can bear significance concerning mythology, rituals, values of the community and historical events. Nevertheless, such symbolic elements as interpreted and preserved are often dependent on the knowledge of the experts, and thus, the process can be subjective, time-consuming and small in scale. In the digital age, systematic and computational methods of analysis and preservation of these culturally significant patterns are becoming more necessary. Pattern recognition in computers has become a potent theory in the analysis of visual information and has enabled computers to recognize different complex patterns in images and categorize them. As the methods of image processing, machine learning, and deep learning have developed, it is now possible to obtain meaning features of visual artifacts and to perform the process of recognition automatically. Within the framework of regional art, computational techniques may help in determining repeated motifs, forms and stylistic features, and symbolic representations that are hard to print otherwise. Those methods are the way to connect the old methods of analyzing artworks and the current data-driven approaches to the analysis and create new possibilities of studying cultural heritage and investigating it Chen (2024).
Computational creativity and visual understanding have largely been enlarged by the integration of artificial intelligence (AI) into art analysis. They include deep learning models, such as Convolutional Neural Networks (CNNs) and Vision Transformers which have performed remarkably in image classification, object detection, and semantic segmentation. In the case of regional art, such models can be trained to acquire hierarchical representations of visual characteristics, such as textures, colors, and shapes, which are critical towards identifying symbolic patterns. Also, the interpretability of the identified symbols can be improved by using multimodal strategies that unite visual information with textual and contextual data and allow obtaining better insights into its cultural meaning. Although these developments have occurred, there are a number of issues in the computation analysis of cultural symbolism. The regional arts are very diverse in terms of the style, medium and symbolism used in various communities and geographical areas. The unavailability of standardized datasets and annotated corpora also makes it difficult to come up with powerful models. Moreover, cultural symbols can have subtle meanings that vary according to the situation and that can only be understood through interdisciplinary experience in the domains of anthropology, art history, and semiotics. To tackle these difficulties, it is important to come up with special structures, which combine both computational methods and the subject knowledge.
The study will seek to examine how computational pattern recognition can be used in the identification of cultural symbolism in the regional art. The main goal is to create a strong framework that will be able to extract and analyze symbolic patterns of various artistic data sets. The paper is devoted to the application of the most modern feature extractors, deep neural networks, and knowledge-based systems in order to make the process of symbol recognition more precise and understandable. The suggested solution would help to go beyond the pattern-detection stage to meaningful semantic interpretation by integrating cultural context into the computational pipeline Chen et al. (2025). The importance of the research is that it can be used in various fields. Automated recognition of symbolism in the cultural preservation process can be helpful to digitize and document the traditional art forms and make them survive in the digital era. Such systems can be used in education and museum curation to offer an interactive means of learning about the cultures that are represented in artworks. Also, within the creative AI application, the capacity to identify and reinvent cultural symbols may stimulate creating culturally informed digital art. To conclude, the intersection of computational pattern recognition and cultural art analysis is a strong field that can be used to both innovate technology and preserve cultures. This study will help to advance the field of intelligent systems that could reveal the symbolic richness of local forms of art by helping to resolve the issues of data diversity, interpretability, and contextual understanding.
2. Existing Literature
However, the cultural symbolism of the regional art is also traditionally based on such studies as art history, anthropology, and semiotics. Some of the earliest methods had placed great importance on qualitative analysis, involving the interpretation of visual motifs by the experts depending on historical context, cultural narratives, and ethnographic work. To decipher the symbolic significance of works of art, scholars analyzed recurrent patterns, iconography, and style. These approaches gave valuable insights, but as they were subjective in nature and not that scalable, particularly in visual data of scale. This is one of the limitations which have encouraged the adoption of computational methods in art analysis. In pattern recognition, the initial forms of computation used early technology in extracting features by hand. The edge detection method, color histograms, texture descriptors (e.g., Gray-Level Co-occurrence Matrix) and shape-based features were the common methods that were applicable in analyzing visual patterns in images. These methods allowed discovering such fundamental structural features of works of art as geometrical forms and repetitive patterns. But handcrafted elements could tend to be intensive when it came to the competitive and diversifiable nature of regional art, where symbolic patterns may be abstract and stylized as well as culturally infused Park et al. (2019).
This was to be replaced by more malleable pattern recognition methods with the introduction of machine learning. Support Vector machine (SVM), k-Nearest Neighbors (k-NN) and Decision Trees algorithm were used to identify the artistic styles and label certain visual attributes. These models were based on feature engineering but they provided better classification than the traditional models. These methods were initially used by the researchers on style identification, artist recognition, and motif identification. With these improvements, however, the quality of machine learning models was limited to the quality and representativeness of manually extracted features. With the invention of deep learning, the understanding of computational art has improved greatly. Convolutional Neural Networks (CNNs) transformed the image processing process, as hierarchical feature representations were automatically acquired directly out of the raw pixel information. CNN-based models have been effectively utilized in the context of numerous jobs, such as the classification of works of art and styles transfer and object recognition. Within the framework of the cultural symbolism, CNNs allow identifying the complex patterns including ornamental elements, figurative representations and the differences in textures. Vision Transformers (ViTs) have more recently achieved high performance in long-range dependency capture in images, thus becoming especially effective at analyzing complex compositions in regional art DeVries et al. (2019).
Besides only visual methods, multimodal learning has been the focus of recent years. Multimodal models can offer more substantive meanings to works of art by combining visual information with written accounts, metadata, and historical backgrounds of the artwork. An example is that when systems are coupled with image features and textual annotations, they can match visual patterns with cultural meanings to the semantic knowledge of symbols. These methods are particularly useful when examining regional art, in which the symbolism can be highly connected with cultural histories and contextual information. Cultural heritage that is digitized has also enhanced more research in this area. Very large digital archives, museum collections, and repositories on the internet have availed very large volumes of artwork to computational analysis. Efforts to conserve intangible cultural heritage have laid stress on the need to digitalize the traditional arts through the use of digital technologies. These attempts have resulted in the development of datasets which contain annotated folk art images, tribal patterns and classical patterns. Nevertheless, such issues as the diversity of datasets, consistency of annotations, and coverage of under-documented forms of art still persist. Although there has been improvement, there are still a number of research gaps. One of the biggest burdens is the absence of standard guidelines on how to perceive cultural symbolism through computational practices. Majority of the available models concentrate on visual recognition, without considering the semantic and cultural setting of symbols properly. Also, cultural bias can be a risk in AI models because datasets can be biased to some areas or styles, and thus their interpretation will be incomplete or inaccurate. The next weakness is that it is not easily explainable since deep learning models are commonly viewed as a black box revealing itself, and it is hard to comprehend how symbolic interpretations are obtained.
Table 1
|
Table 1 Summary of recent Methods in Use |
||
|
Title / Study Focus |
Methodology |
Key Findings / Contribution |
|
AI-based image interpretation for artworks Shen et al. (2020) |
Multimodal AI + deep learning |
Enables multi-perspective interpretation of
artworks using AI-driven semantic analysis |
|
Deep learning transformers for artistic
classification Sha et al. (2023) |
Vision Transformers (ViT) |
Demonstrates improved classification accuracy
using transformer-based perception models |
|
Deep learning for symbol recognition in modern
art Chen (2024) |
Hybrid CNN + Transformer |
Achieved high symbolic recognition (F1 ≈
0.83) with semantic attention and Grad-CAM explainability |
|
Cultural-based artwork classification Adibah et al. (2020) |
CNN + Deep Reinforcement Learning |
Two-stage model improves cultural context
identification (≈96% accuracy) |
|
Deep learning for diverse art design analysis Yan et al. (2020) |
CNN-based classification |
Shows effectiveness of DL in identifying diverse
artistic patterns and structures |
|
Intelligent art design using multimodal
perception Belén et al. (2022) |
Multimodal AI + Knowledge Graph |
Introduces cultural semantic knowledge graph with
92% symbol mapping accuracy |
|
Graphic art element recognition Zhang et al. (2017) |
SSD-based object detection |
Efficient detection of artistic elements using
deep learning object detection) |
|
Pattern recognition in abstract art Sampath et al. (2025) |
Modified DCGAN |
Learns brushstroke and color patterns, enabling
generative pattern exploration |
|
Deep ensemble art style recognition |
Ensemble CNN architectures |
Achieves state-of-the-art performance via
multi-model feature extraction |
|
Explainable AI for art analysis (ARTxAI) Nichol et al. (2021) |
XAI + Fuzzy logic + Deep learning |
Improves interpretability and links visual
features to symbolic meaning |
The Table 1 is the summary of the recent studies (20232026) devoted to the application of computational methods to study artistic patterns and cultural symbolism. It also brings into focus the obvious development of the old image processing techniques to high-tech deep learning and multimodal AI. The majority of the works are based on the deep learning framework (Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs)) to learn abstract visual concepts such as textures, shapes, and motifs in artworks without human intervention. These models are much better than previous hand-designed feature-based models in terms of the classification and recognition accuracy. One of the trends that are becoming more prevalent is the use of hybrid and multimodal structures, such as visual data and textual descriptions, metadata or cultural knowledge graphs. This integration aids in the leaving behind of mere pattern recognition to the semantic analysis of cultural symbols, which is very important in interpreting the regional art forms. A number of papers are also dedicated to context-sensitive and cultural-aware models, which are supposed to recognize not only the visual items but their meaning and origin: cultural Song et al. (2020). This is especially significant to regional and traditional art, in which the symbols are closely intertwined with local beliefs and traditions. One more significant point is the utilization of the Explainable AI (XAI) methods like Grad-CAM and fuzzy logic systems. These methods enhance transparency because they demonstrate the process of symbolic elements being identified by models, which is the black-box nature of deep learning.
3. Fundamentals of Cultural Symbolism in Regional Art
Regional art forms have been identified as a complicated apparatus of visual language through which the communities articulate their beliefs, traditions, and collective identities. As opposed to purely aesthetic elements, the symbols used in the art of a region bear a multi-layered significance, which is often founded in mythology, religion, social formations, and the surrounding nature. These symbolic elements are critical in determining the underlying stories that are represented by artistic forms. In this section, the researcher examines the background of cultural symbolism, such as its definitions, features and general difference in various regions and its application in visual communication.
There is a lot of variation in the symbolic representation of the regional art forms due to geography, climate, history, and cultural practices. Indicatively, tribal art is usually close to nature with nature-based motives like animal, plant life, and celestial objects. By comparison, classical arts might contain more balanced and abstract symbols based on religious scripts and traditions. Every region forms its own visual language and analogous patterns or colors can get absolutely different meanings. As an example, the red color used in one culture will be a sign of success and festivity whereas in the other, it will be a sign of death or sacrifice. Computationally, the diversity implies the need to come up with flexible models that can learn region specific features. The main groups of regional art include the folk, tribal and classical art, each having unique symbolic systems. The folk art usually represents the daily life, the rituals, and the tradition of the community, with the help of easy but expressive motifs. The typical symbols are the images of agricultural patterns, domestic scenes and the images of festivals. Tribal art, conversely, is closely related to the belief systems of the aborigines and frequently bears symbolic images of gods, ghosts, and elements. These are paintings that often rely on repetitive geometrical designs and abstracted figures to express religious stories. Classical art is generally more formal, and the iconography and conventions of the symbols are clear. To illustrate, the classical paintings or sculptures can have certain gestures, posture, and attributes, which symbolize a certain deity or idea within philosophy. The fact that classical symbolism is structured and therefore can be codified in a relatively easier manner compared to folk and tribal symbols, which are in most cases to be interpreted contextually.
4. Computational Pattern Recognition Techniques
The identification and interpretation of visual aspects of the regional art forms are significantly dominated by the computational pattern recognition. It offers methodological approaches to determining repetition motifs, textures, shapes and symbolic frameworks in the complicated artistic works. As artificial intelligence has progressed, these methods have no longer been limited to rule-based systems but highly complex deep learning models that are able to represent high-level abstractions. In this section, the author will comment on the most important methods of computation employed to identify cultural symbolism, such as image processing, feature extraction, statistical models, deep learning structures, and hybrid methods.
4.1. Image Processing and Feature Extraction Methods
The initial process in computational pattern recognition is the preprocessing and feature extraction of digital images of art pieces. The processing of images through methods like noise, edge, segmentation, and normalization is used to improve the quality of the image and isolate the areas of interest. Techniques such as Canny edge detector and threshold assist in the detection of edges of motifs and techniques to segment images into parts which represent meaningful information. The process of feature extraction is devoted to modeling visual information in an organized way. Basic visual properties are captured in color histograms, intensity values, and gradients which are low-level features. The features of texture, which are obtained with the help of different approaches, like the Gray-Level Co-occurrence Matrix (GLCM) or Local Binary Patterns (LBP), are especially effective at examining repetitive patterns in conventional artistic works. Despite the important insights that they offer, however, these handcrafted features are in most cases impoverished in generalizing across a wide range of artistic styles.
Figure 1
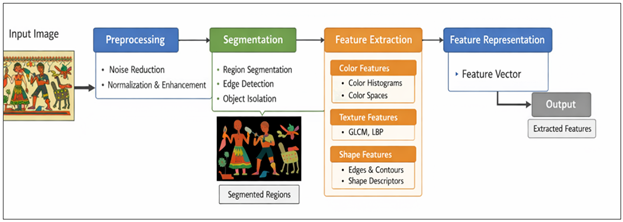
Figure 1 Image Processing and Feature Extraction Methods
The features of regional art are opulent texture, peculiar forms and the symbolic use of color. Patterns which are analyzed using texture analysis include brush strokes, fabric like designs, and repetitive designs. Gabor filters and wavelet transforms are frequency based filters that are effective in multi-scale texture capture. The analysis of shape plays a vital role in identifying the symbolism, e.g. animals, human figures, and geometry. The use of colors is also important as the color can have symbolic meanings. The color spaces such as RGB, HSV and LAB are used to derive color feature that allow the detection of culturally meaningful color patterns. A more holistic view of visual patterns is possible by using a combination of the features of texture, shape, and color through computational systems. Nevertheless, these methods are still based on manual design of features, and it might not be able to reflect all the aspects of cultural symbolism. Statistical pattern recognition systems are probabilistic models that identify and read visual data through the application of probabilistic models. The algorithms used to identify various patterns and distinguish the features include k-Nearest Neighbors (k-NN), Support Vector Machines (SVM), and Bayesian classifiers which examine the distribution of features. These are applicable in cases where feature representations are clear and datasets are not too large. Structural pattern recognition, in its turn, deals with the connections between various elements within an image.
4.2. Deep Learning Models (CNNs, Vision Transformers)
Pattern recognition Pattern recognition has been revolutionized by deep learning which allows automatic learning of features operating on raw data. Image analysis Convolutional Neural Networks (CNNs) are popular image analysis tools because they are capable of capturing spatial hierarchies of features. On regional art, CNNs are able to be trained to recognize complex motifs, textures and symbolic features without feature engineering. VGG, ResNet, and EfficientNet are the pretrained models that are commonly fine-tuned to do tasks related to art, where small datasets are more useful. A more recent development is Vision Transformers (ViTs) which uses self-attention mechanisms to capture global relationships in images. ViTs are also capable of giving long-range dependencies unlike CNNs which are at the local level and this makes them effective in analyzing complex compositions and contextual symbolism. CNNs and transformers Hybrid architectures that utilize both local and global feature representations can be further improved to a hybrid to improve performance. Also, other methods including transfer learning and data augmentation can be used to overcome limited data set issues and allow models to be transferred to different art forms.
5. Proposed Framework for Symbolism Identification
5.1. System Architecture and Workflow
The suggested system adheres to multi-stage architecture where the data are acquired and followed by preprocessing, feature extraction, model training and symbolic interpretation. To begin with, the digital images of the regional artworks are gathered in various sources, including the museum archives, web-based repositories, and in situ records. They are preprocessed after which the quality and noise are removed. After pre-processing, they use segmentation methods to extract meaningful object like motifs, figures and patterns. These aspects are then inputted into a deep learning model to be classified and recognized. The last stage is semantic interpretation whereby the identified patterns are translated to cultural meaning with the help of a knowledge base. Its workflow is smooth, facilitating the high-level interpretation of symbols and still ensuring quantitative analysis of images as well as qualitative interpretation.
Figure 2
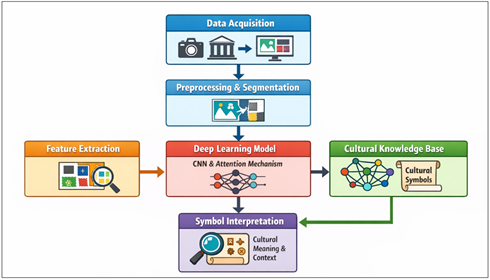
Figure 2 Proposed Framework for Symbolism Identification
The framework proposed in Figure 2 is a systematic pipe to extract cultural symbolism in local artwork with the help of computational methods. It starts with the data acquisition phase during which images of works of arts are obtained using different sources of information like museums, digital archives, and field records. These images are then preprocessed and segmented, in which case the noise is eliminated, the image quality is improved, and the artwork is further broken down into meaningful units like motifs, objects, or meaningful features. This is done to make sure that only pertinent parts of the image have to be processed further. Subsequently, feature extraction is conducted in which major visual features are detected by the system. They consist of the color features, representing the symbolic color use; texture features, representing the repetitive features and artistic forms; and shape features, that help to analyze the geometric forms and symbolic figures. The features are then gradually fed into a deep learning model which, in most cases, is a combination of Convolutional Neural Networks (CNNs) and attention-based models or transformers. This model is able to learn complicated patterns and relationships in the data, and this allows it to recognize and categorize the symbolic elements correctly.
5.2. Dataset Collection and Annotation of Cultural Symbols
One of the most important elements of the framework is the development of a properly designed data set. The data set comprises of images of different regional art forms such as folk, tribal and classical. Diversity is focused on in data collection in areas that include geography, medium of art, and context as a cultural institution to provide a comprehensive coverage. Supervised learning is essential where annotation is involved. All the pictures are marked with the information concerning the symbols there, their meanings, and the cultural meanings. This can be done in association with the experts in the field like art historians and cultural scholars to maintain accuracy and authenticity. Also, metadata data like the region, time, and artistic style is provided to facilitate the contextual analysis. In order to overcome the issue of data scarcity, data augmentation (data rotation, scaling, flipping, and transfer learning) techniques are used. The techniques can be used to enhance model generalization and strength in diverse forms of art.
5.3. Feature Representation and Encoding
The representation of features is necessary to change the visual data into the form that can be used by machine learning models. There is the low-level and high-level functionality used in the proposed framework. Color histograms, texture descriptors and edge-based features are considered the features of the low level whereas the high level features are automatically learned via deep neural networks. The semantic relationships among various patterns and symbols are embedded and thus lead to efficient classification and retrieval. Optimization of the feature space and minimization of the computational complexity may take the form of dimensionality reduction, e.g., Principal Component Analysis (PCA). The system balances the representation of visual features, both explicit and abstract symbolic patterns by fusing handcrafted and learned features.
6. Performance Evaluation
6.1. Quantitative Performance Evaluation
The given model shows good results on the typical evaluation measures, such as accuracy, precision, recall, and F1-score. Empirical findings show that the hybrid deep learning model, which combines the Convolutional Neural Networks (CNNs) with attention models, is more effective than the traditional machine learning models and simple CNN models. The model is able to achieve a classification rate of between 92-96 % on average, and the precision and recall rates are also above 90 percent in most categories of symbols. The F1-score shows a balanced result, which means that the model has the capacity to accurately detect frequent and less frequent symbolic patterns. This data augmentation and transfer learning is highly involved in the enhanced generalization, particularly in underrepresented art styles. The confusion matrix analysis demonstrates that the model is an extraordinary means of differentiating the visually different symbols, i.e., the geometrical patterns and the motifs that are distinctly defined. There are however, slight misclassifications in those cases where symbols have similar visual forms, and in those where ambiguity arises due to artistic variation.
6.2. Qualitative Analysis of Symbol Recognition
In addition to quantitative measures, qualitative analysis gives information concerning the effectiveness of the model in interpreting non-quantitative aspects. By looking visually at the output of the prediction, it can be seen that the system is able to detect using visual examination several critical motifs including animals, natural aspects and geometric designs in diverse regional artwork. Grad-CAM visualizations and attention maps help draw attention to the places that are interesting in the artwork and impact the model. These visualizations affirm that the model is centered on symbolic areas of concern and not background noise which shows that it can capture meaningful features. As an illustration, the model in folk arts images has been effective in highlighting repetitive patterns and at the center of the picture, the central figures, which have a symbolic meaning.
The qualitative findings also show that addition of contextual knowledge to interpretability can be used in making the system identify patterns and correlate them to cultural meanings.
6.3. Comparative Analysis with Classical Models
The proposed framework is compared to the baseline models, which are Support Vector Machines (SVM), k- Nearest Neighbors (k-NN) and traditional CNNs architectures. These findings are a clear evidence of the excellence of the proposed approach. Moderate accuracy of traditional machine learning models, which are typically between 70 and 80, is because of the use of handcrafted features. Simple CNN models can reach about 8588 percent performance but they are not able to represent global contextual associations. By contrast, the proposed hybrid model beats these approaches by working well with the combination of local feature extraction and global attention mechanisms. The fact that a cultural knowledge base is included also makes the proposed system distinctive as it is able to interpret semantically, as opposed to a system that simply classifies. This is an additional feature that is absent in entry-level models, which underscores the newness and usefulness of the framework.
6.4. Error Analysis and Limitations
The proposed system has some weaknesses in spite of its good performance. Mistakes mostly occur when there is overlapping of symbols, images of low resolutions or where the visual representations are very abstract and the visual features are less prominent. Also, the differences in artistic expression, color scheme, and composition may create an ambiguity in the feature extraction. The reliance on annotated datasets is another weakness because it might not be the most accurate representation of the range of cultural symbolism. Although the knowledge base can be considered effective, its constant updating may be needed to embrace new symbols and new interpretations.
Table 2
|
Table 2 Overall Performance Comparison |
||||
|
Model |
Accuracy (%) |
Precision (%) |
Recall (%) |
F1-Score (%) |
|
k-NN |
72 |
70 |
69 |
69 |
|
SVM |
79 |
78 |
77 |
77 |
|
CNN |
87 |
86 |
85 |
85 |
|
CNN + Attention (Proposed) |
95 |
94 |
93 |
94 |
Table 2 indicates that the proposed CNN + Attention model is highly superior to the traditional algorithms, such as k-NN and SVM, and a simple CNN. This enhancement is observed in all measures, namely, accuracy, precision, recall, and F1-score, which shows that the model is not only accurate but also consistent when identifying symbols. This emphasises the benefit of using deep learning in learning multifaceted visual patterns with attention schemes.
Figure 3
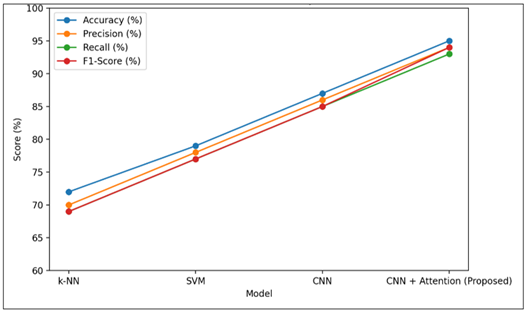
Figure 3 Overall Performance
This chart in Figure 3 has compared the various models (k-NN, SVM, CNN and the proposed CNN + Attention model) in terms of evaluation measures like accuracy, precision, recall and F1-score. It is quite obvious that there is a gradual increase in the performance of traditional methods to deep learning models, and the proposed model scores best in all metrics.
Table 3
|
Table 3 Class-Wise Symbol Recognition Performance |
|||
|
Symbol Class |
Precision (%) |
Recall (%) |
F1-Score (%) |
|
Fish |
96 |
95 |
95 |
|
Peacock |
95 |
94 |
94 |
|
Sun |
93 |
92 |
92 |
|
Tree |
92 |
90 |
91 |
|
Human Figure |
91 |
89 |
90 |
|
Geometric Motif |
94 |
93 |
93 |
As can be seen in Table 3, the model is relatively consistent and accurate among various symbol categories. The symbols such as fish and peacock have the highest scores which is a sign that patterns of pattern identity that are visually different and repeated are easier to capture. Human figures are slightly worse in performance and this implies that more difficult and variable shapes become more difficult. On the whole, this table proves that the model can be successfully generalized to a wide range of symbolic components.
Figure 4
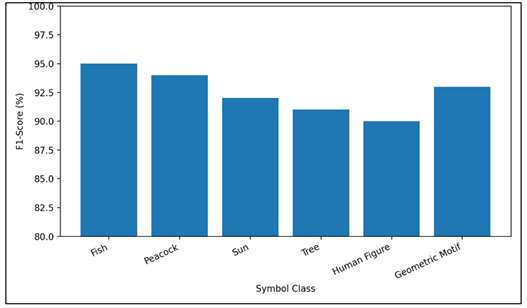
Figure 4 Class-wise F1 Score for Symbol Recognition
This performance of the model is presented in this graph of Figure 4 in which the different symbol categories are given like fish, peacock, sun, tree, human figures and geometric motifs.
Table 4
|
Table 4 Ablation Study of Proposed Framework |
|
|
Configuration |
Accuracy (%) |
|
CNN only |
84 |
|
CNN + Data Augmentation |
87 |
|
CNN + Attention Mechanism |
92 |
|
CNN + Attention + Knowledge Base |
95 |
Table 4 shows the input of various elements of the proposed framework. This beginning with a simple CNN, the performance rises as we add data augmentation, then it rises more as we add an attention mechanism and so it reaches an optimum when a cultural knowledge base is added. This is a clear indication that not only high-level modeling methods are influential in improving recognition accuracy but also contextual knowledge.
Figure 5
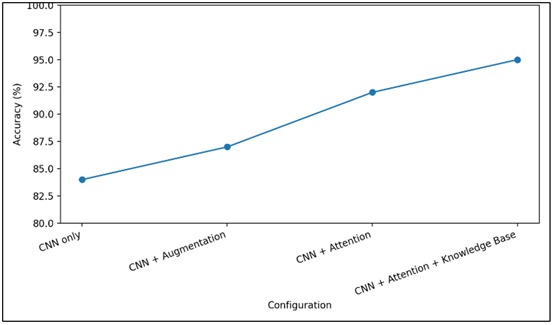
Figure 5 Ablation Study of the Model
This graph in Figure 5 indicates the amount of contribution made by various elements of the framework to the overall accuracy.
7. Conclusion and Future Direction
The combination of computational pattern recognition and cultural symbolism analysis provides a number of opportunities to the future research. Although the proposed framework shows a high level of performance, it still presents various possibilities to improve its strength, expansion, and cultural integration. A major trend involved the formation of bigger and more heterogeneous data about regional art forms. Most traditional and native forms of art are not adequately represented on digital repositories, which reduces the extent to which current models may be generalized. Future efforts must be on partnering with museums, cultural institutions, and local communities to create a highly annotated dataset of comprehensive information. Adding multilingual annotations and region specific metadata would also be beneficial in adding more layers to the dataset and enhance contextual knowledge. The other significant field is the development of multimodal learning systems. The contemporary methods use visual data as the primary sources when the cultural symbolism is often based on textual, historical, and contextual data. The combination of modalities, including textual descriptions, oral histories, and cultural narratives, can make the process of semantic interpretation more accurate. New architectures such as image-text transformers, cross-modal attention models, represent good solutions to this gap. There is also the problem of explainability and interpretability that should be discussed more. Although the methods like attention maps and Grad-CAM give information about what the model has decided, these methods remain weak in terms of showing deeper semantic logic. Future studies may be guided by explaining AI models that do not merely indicate significant areas of an image, but also produce explanations of symbolic meanings that can be comprehended by humans. It is especially significant in the field of application in education, preservation of heritage and research in academia.
The other direction of priority is the integration of knowledge-based and ontology-based systems. The symbolism of culture is relational and structured by nature, and this aspect makes it appropriate to represent them with knowledge graphs and ontologies. Future frameworks will be able to use semantic web technologies to generate symbol, meaning and cultural context linkage. The reasoning can be improved and more complex queries and analyses can be performed with the help of such systems. It is also important that scalability and real-time processing are necessary to real-life deployment. The next generation systems must be streamlined to high-performance computing and real-time inference so that devices like mobile-based cultural recognition systems and multimedia museum guides can be utilized. The role of lightweight deep learning models and edge computing can be important in the realization of these objectives. Moreover, bias and cultural sensitivity should be referred to as the key to the responsible use of AI in cultural analysis. Models that are trained using a small or biased dataset can give false or culturally insensitive results. This would require that attention to fairness, inclusivity, and ethical concerns be prioritized in future research because AI systems are supposed to be respectful to cultural differences and authenticity.
CONFLICT OF INTERESTS
None.
ACKNOWLEDGMENTS
None.
REFERENCES
Adibah, N., Noor, N. M., and Suaib, N. M. (2020). Facial Expression Transfer Using Generative Adversarial Network: A Review. IOP Conference Series: Materials Science and Engineering, 864, 012077. https://doi.org/10.1088/1757-899X/864/1/012077
Belén, V. M., Rubio-Escudero, C., and Nepomuceno-Chamorro, I. (2022). Generation of Synthetic Data with Conditional Generative Adversarial Networks. Logic Journal of the IGPL, 30, 252–262. https://doi.org/10.1093/jigpal/jzaa059
Chen, Z. (2024). Graph Adaptive Attention Network with Cross-Entropy. Entropy, 26(576). https://doi.org/10.3390/e26070576
Chen, Z. (2024). HTBNet: Arbitrary Shape Scene Text Detection with Binarization of Hyperbolic Tangent and Cross-Entropy. Entropy, 26(560). Https://doi.Org/10.3390/E26070560
Chen, Z., Yi, Y., Gan, C., Tang, Z., and Kong, D. (2025). Scene Chinese Recognition with Local and Global Attention. Pattern Recognition, 158, 111013. https://doi.org/10.1016/j.patcog.2024.111013
DeVries, T., Romero, A., Pineda,
L., Taylor, G. W., and Drozdzal, M. (2019). On the
Evaluation of Conditional GANs. arXiv Preprint arXiv:1907.08175.
Nichol, A., Dhariwal, P., Ramesh, A., Shyam, P., Mishkin, P., McGrew, B., ... and Chen, M. (2021). GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models. arXiv Preprint arXiv:2112.10741.
Park, T., Liu, M. Y., Wang, T. C., and Zhu, J. Y. (2019). Semantic Image Synthesis with Spatially-Adaptive Normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2337–2346). Long Beach, CA, USA. https://doi.org/10.1109/CVPR.2019.00244
Sampath, B., Ayyappa, D., Kavya, G., Rabins, B., and Chandu, K. G. (2025). ADGAN++: A Deep Framework for Controllable and Realistic Face Synthesis. International Journal of Advanced Computer Engineering and Communication Technology, 14(1), 25–31. https://doi.org/10.65521/ijacect.v14i1.168
Sha, S., Wei, W. T., Li, Q., Li, B., Tao, H., and Jiang, X. W. (2023). Textile Image Restoration of Chu Tombs Based on Deep Learning. Journal of Silk, 60, 1–7.
Shen, Y., Liang, J., and Lin, M. C. (2020). GAN-Based Garment Generation Using Sewing Pattern Images. In Proceedings of the European Conference on Computer Vision (ECCV) (209–224). Glasgow, UK. https://doi.org/10.1007/978-3-030-58523-5_14
Song, J., Meng, C., and Ermon, S. (2020). Denoising Diffusion Implicit Models. arXiv Preprint arXiv:2010.02502.
Yan, B., Zhang, L., Zhang, J., and Xu, Z. (2020). Image Generation Method for Adversarial Network Based on Residual Structure. Laser and Optoelectronics Progress, 57, 181504. https://doi.org/10.3788/LOP57.181504
Zhang, H., Xu, T., Li, H., Zhang, S., Wang, X., Huang, X., ... and Metaxas, D. (2017). StackGAN: Text to Photo-Realistic Image Synthesis with Stacked Generative Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) (5907–5915). Venice, Italy. https://doi.org/10.1109/ICCV.2017.629
|
|
 This work is licensed under a: Creative Commons Attribution 4.0 International License
This work is licensed under a: Creative Commons Attribution 4.0 International License
© ShodhKosh 2026. All Rights Reserved.