ShodhKosh: Journal of Visual and Performing ArtsISSN (Online): 2582-7472
|
|
Measuring Creativity in Contemporary Art via AI Models
Ashish Verma 1![]()
![]() ,
YuvrajSinh Sindha 2
,
YuvrajSinh Sindha 2![]()
![]() ,
Rashmi Manhas 3
,
Rashmi Manhas 3![]() , R. Elankavi 4
, R. Elankavi 4![]()
![]() ,
Saudagar Subhash Barde 5
,
Saudagar Subhash Barde 5![]() , Dr. Kunal Meher 6
, Dr. Kunal Meher 6![]()
![]()
1 Centre
of Research Impact and Outcome, Chitkara University, Rajpura- 140417, Punjab,
India
2 Assistant
Professor, Department of Interior Design, Parul Institute of Design, Parul
University, Vadodara, Gujarat, India
3 Assistant Professor, School of Business Management, Noida
International University, India
4 Associate Professor, Department of Computer Science and Engineering, Aarupadai Veedu Institute of Technology, Vinayaka Mission’s
Research Foundation (DU), Tamil Nadu, India
5 Department of Information Technology Vishwakarma Institute of
Technology, Pune, Maharashtra, 411037, India
6 Assistant Professor, UGDX School of Technology, ATLAS Skill Tech
University, Mumbai, Maharashtra, India
|
|
|
ABSTRACT |
|
|
The process of
measuring creativity in modern art has mostly been based on subjective expert
opinion, cultural background and qualitative interpretations, which although
they may be valuable, are usually not scalable, consistent and repeatable. As
digital art practices and art datasets continue to expand at a very high
rate, there is an increasing demand to have computational systems that can
enable the systematic evaluation of the features of creativity without
compromising artistic subtleties. In the present paper, the author suggests
an AI-enabled creativity measurement framework which is a combination of
computer vision, natural language processing, and multimodal learning to
measure creativity in modern artworks. The framework conceptualizes creativity
as a multidimensional construct that entails visual novelty, stylistic
deviance, conceptual richness, narrative novelty and contextual topicality.
Deep convolutional and transformer-based vision models are used to extract
features of visual analysis that include color harmony, compositional
complexity, variation of texture and deviation of style. The conceptual and
semantic levels are represented by the use of NLP
models on the texts of artists, exhibition, and critical descriptions, which
allows analyzing originality, metaphor density, and coherence of the theme.
Multimodal visionlanguage models also match a
visual and textual representation to generate an overall creativity score,
one that is holistic that captures the perceptual as well as interpretative elements
of art. The suggested approach is compared to the baseline statistical and
single-modality models in terms of the quantitative indicators of novelty
indices, semantic divergence scores, cross-modal coherence, and accuracy in
the classification of creativity. |
|||
|
Received 17 June 2025 Accepted 01 October 2025 Published 28 December 2025 Corresponding Author Ashish
Verma, ashish.verma.orp@chitkara.edu.in
DOI 10.29121/shodhkosh.v6.i5s.2025.6923 Funding: This research
received no specific grant from any funding agency in the public, commercial,
or not-for-profit sectors. Copyright: © 2025 The
Author(s). This work is licensed under a Creative Commons
Attribution 4.0 International License. With the
license CC-BY, authors retain the copyright, allowing anyone to download,
reuse, re-print, modify, distribute, and/or copy their contribution. The work
must be properly attributed to its author.
|
|||
|
Keywords: Creativity Measurement, Contemporary Art, Artificial
Intelligence, Multimodal Learning, Art Analytics |
|||


1. INTRODUCTION
The center of contemporary art is the creativity which defines the way artists react to the social change, the culture, technological advancement and the expression of themselves. Creativity is no longer simply the matter of technical skill or artistic appeal in a modern practice of art, but is a multifaceted process involving originality, conceptual richness, awareness of context and expressive will. Modern art tends to be unconventional, multimedia, and involve viewers with multiple layers of meaning, and therefore, the measurement of creativity is a very subjective and sensitive process. Historically, creative activity has been assessed by the expert opinion, the judgment of the curator, the review of the colleagues, and the reception of the audience, which relied on the subjective interpretation and positioning in the culture. Although qualitative evaluation can be deemed as a fundamental part of artistic value, it is limited in scalability, consistency, and transparency to a significant degree Shao et al. (2024). Because the online forms of exhibition, AI-created art, and various digital technologies are rapidly increasing the sheer amount and range of contemporary art, the idea of the human factor in art evaluation becomes harder and harder to maintain. The variation in critical attitudes, cultural prejudices, and familiarity with the context usually leads to the variation in evaluation especially where the artworks have different social or geographical origins. Such issues have prompted scholars and practitioners to examine computer-based methods that can facilitate, enhance and formalize creativity judgement and not reduce artistry Leong and Zhang (2025). Figure 1 depicts system architecture of AI-based model of creativity evaluation. Artificial intelligence provides hopeful means to deal with this challenge as it allows one to analyze artistic characteristics of works in a data-driven way in the visual, textual, and contextual level. Computer vision has advanced enough that it is now possible to analyze the use of color, composition, texture, form and deviation of style on a large scale and such techniques as natural language processing are now able to analyse the semantics of artist statements, curatorial text and critical discourse.
Figure 1

Figure 1 System Architecture of AI-Driven Creativity
Evaluation Model
Later on, the concept of multimodal and vision language models has been capable of interpreting visual and textual information simultaneously, matching features of perception with conceptual narratives. New opportunities related to these developments emerge in defining creativity as an objective, multidimensional construct and not a subjective concept. But it is not that easy to quantify creativity using AI. Creativity by its very definition is abstract, culturally contextual and incapable of being formalized too strictly Leong and Zhang (2025). When narrowed down to one numerical score there is the risk of oversimplification and might overlook the social, historical and emotional aspects that shape artistic practice. Thus, the current studies focus on hybrid frameworks which are balanced in terms of quantitative indicators, and interpretability, transparency, and contextual sensitivity. Instead of substituting human judgment, AI-based creativity measurement is being considered as a tool of decision support that can show trends, emphasize novelty and offer comparative information on large sets of artworks. In this framework, the current research is aimed at quantifying creativity in the field of the modern art through the use of AI models through the combination of multimodal data sources and modern learning architectures Lou (2023). It is suggested that the key assumption is that the concept of creativity can be operationalized with the help of intersecting dimensions that include visual novelty, stylistic deviation, semantic richness, conceptual originality, and contextual alignment. Through a series of feature extraction and analysis AI systems can provide reproducible and explainable features of creativity that can be applied to art criticism, curation, education, and digital archiving Guo et al. (2023).
2. Related Work
2.1. Traditional qualitative methods in art criticism and assessment
The conventional methods of assessing artistic creativity have been based on the qualitative interpretation and the expert judgment and the analysis of the context. Critical writing on art, reviews by curators, article writing in art history make specific attention to the subjective approach towards works of art where originality, emotional appeal, conceptualism, and cultural meaning are given priority. Art works are commonly placed in their context in terms of the larger artistic movement, the history of art and society as a whole, in which creativity can be seen as a conversation between the artist, the work of art, and society Cheng (2022). Formal analysis, color, form and technique are analysed by methods like formal analysis, symbolism and meaning are analyzed by iconographic and iconological method. The creative evaluation is also carried out through peer review, exhibition selection by a jury and institutional validation; which reflects the consensus in an art community. Qualitative methods are limited by the question of consistency and scalability, although they are quite in-depth and culturally sensitive. Different critics can have a vast range of interpretations, owing to the difference in aesthetic philosophy, cultural orientation or institutional membership Rombach et al. (2022). Evaluation criteria are usually not explicit but implicit and thus they are not easily reproducible. With contemporary art moving towards the embrace of digital media, generative processes, and interdisciplinary practices, the field of purely qualitative evaluation is finding it difficult to keep up with volume and variety. Although these approaches are considered to be invaluable to the subtle comprehension, their subjectivity inspires complementary strategies that can provide formalized, transparent, and comparative knowledge without dispossessing the human knowledge Marcus et al. (2022).
2.2. Quantitative and Semi-Quantitative Creativity Metrics
Attempts to measure creativity, especially quantitatively, have resulted in the creation of quantitative and semi-quantitative measures, especially in psychology, design studies, and computational creativity research. Earlier models were able to conceptualize creativity based on the dimensions of novelty, usefulness and surprise, which were eventually measured in the form of rating scales, scoring rubrics, and behavioral indices. Semi-quantitative approaches in visual arts have also involved expert ratings of novelty, sophistication, and beauty, frequently based upon Likert-scale assessment of such aspects Borji (2023). Diversity indices, and measures of stylistic distance, entropy-based counts of novelty in artistic outputs, and statistical metrics of variation have been used to quantitatively measure variation in works of art. More formal systems like Consensual Assessment Technique are based on human judgment and standardized criteria, and allow some comparability of works of art. The use of algorithmic measures in digital art and generative art is used in order to evaluate the non-fidelity to training data, feature rarity, or the predictability of form. Although these measures are good at numerical expression of creative properties, they tend to measure single dimensional aspects of creativity Westermann and Gupta (2023). Symbolic meaning, conceptual depth and cultural resonance are hard to measure on the basis of mere indicators. Furthermore, dependence on preset measures may be a source of bias in favor of quantifiable characteristics at the expense of experience. Consequently, quantitative and semi-quantitative methods are also viewed as complementary which are useful when combined with more complete data descriptions and dynamic computational frameworks Giannini and Bowen (2023).
2.3. AI and Machine Learning in Art Analysis
The emergence of recent progress in artificial intelligence and machine learning has greatly broadened the range of computational art critique. Visual attributes, such as palette of colors, and texture patterns, compositional structure, and stylistic influence have been used to evaluate computer vision models (convolutional neural networks, vision transformers, etc.) on large art datasets. These models provide automatic classification of the art styles, identification of the visual novelty and the identification of styles across time. Likewise advances in natural language processing have enabled semantic analysis of artist statements, exhibition catalogues and critical reviews, enabling machines to deduce an interest in a particular topic, a complexity of conceptualisation, and originality of narrative Horton et al. (2023). Later, there have been introduced multimodal learning techniques which combine visual and textual data and match images and words to create complete representation of the art pieces. The vision-language models facilitate the reasoning across modalities, and therefore coherence of visual expression and intent can be evaluated. Explainable AI methods also increase interpretability by calling out features that lead to creative evaluation Liu et al. (2024). In spite of this progress it is still hard to model cultural considerations, subjective meaning and ethical considerations. The risks of biased training data, deep models being opaque, and the danger of diminishing creativity in favor of algorithmic outputs are something that should be carefully designed to be part of a framework. Table 1 is a summary of AI-based approaches to the measurement of creativity in the contemporary art. However, AI-based art analysis is a very strong basis of scalable, transparent and multidimensional creativity measurement in cases of combining it with human-based interpretive practices.
Table 1
|
Table 1 Summary on Measuring Creativity in Contemporary Art Using AI Models |
||||
|
Art Form |
Core Methodology |
Creativity Dimensions
Evaluated |
Key Findings |
Limitations |
|
Digital and Media Art |
Cultural analytics |
Visual diversity, novelty |
Large-scale visual pattern
discovery |
Limited conceptual analysis |
|
Fine Art Painting Kannen et al. (2024) |
Style deviation analysis |
Novelty, style originality |
Quantified deviation from
art styles |
Ignores artist intent |
|
Computational Creativity |
Rule-based evaluation |
Novelty, value, surprise |
Formalized creativity
criteria |
Not data-driven |
|
Art History |
Style classification |
Stylistic divergence |
Tracks evolution of styles |
No semantic context |
|
Visual Art Wei et al. (2024) |
Neural style analysis |
Style abstraction |
Effective style
representation |
Not creativity-focused |
|
Generative Art |
Process-based creativity |
Novelty, emergence |
Links process to creativity |
Hard to generalize |
|
Contemporary Art Rhem (2023) |
Aesthetic scoring |
Visual appeal, originality |
Predicts aesthetic scores |
Subjective ground truth |
|
Photography and Art |
Attribute learning |
Style, composition |
Learns visual style cues |
Limited abstraction |
|
Conceptual Art |
Semantic analysis |
Conceptual depth |
Captures narrative
originality |
Ignores visual form |
|
AI-Generated Art Santoni de Sio (2024) |
Novelty detection |
Visual novelty |
Detects out-of-distribution
art |
No human alignment |
|
Multimodal Art |
Vision–language alignment |
Cross-modal creativity |
Strong visual–semantic
alignment |
No explicit creativity score |
|
Art and AI Theory |
Critical framework |
Creativity interpretation |
Defines AI creativity roles |
No experiments |
|
Digital Art Archives |
Multimodal learning |
Contextual originality |
Improved archive analysis |
Dataset bias |
|
Contemporary Art |
Multimodal creativity modeling |
Novelty, style, concept,
context |
Holistic, explainable
assessment |
Requires expert labels |
3. Proposed AI-Based Creativity Measurement Framework
3.1. Overall system architecture and workflow
The suggested AI-based creativity measurement system can be described as a modular and end-to-end system that is able to integrate the data acquisition, multimodal feature learning, creativity inference, and interpretability layers. The workflow starts with the input of various artistic data such as visual artworks and related textual data and context, which are preprocessed and normalised in order to be consistent across the sources. The architecture follows a layered structure, which has input processing, feature extraction, multimodal fusion, creativity scoring and explanation modules. Modality-specific deep learning models are independently applied to visual and textual streams before making them visually or textually compatible. A combination of regression and classification heads is used to compute creativity inference based on multidimensional creativity indicators (i.e. novelty, conceptual depth and stylistic divergence). An explainability layer is used to increase transparency, which means that attention visualization and feature attribution techniques are introduced, enabling one to understand which visual or textual elements have the strongest impact on the assessment of creativity.
3.2. Multimodal Data Inputs (Images, Text, Metadata, Artist Statements)
Contemporary art creativity is necessarily multimodal and demands visual, textual and contextual information to engage the entire expressive potential of art. The suggested framework thus embraces the different types of data input, where images are the main embodiment of artistic work. The visual data of a high resolution allow studying the color composition, its form, texture, the arrangement of space, and stylistic elements in detail. In addition to visual messages, written materials, like statements of artists, descriptions of exhibitions, and reviews, give valuable information on conceptual intent, thematic contextualisation and narrative novelty. These readings are necessary to comprehending the symbolic and intellectual aspects of creativity that cannot be observed by looking at pictures only. Metadata also adds additional information to the analysis by providing contextual details, such as date of creation, medium, artistic style, geographic location and exhibition history. This information promotes temporal and cultural contextualization, and creativity can be assessed in more or less justified ways against the artistic standards and historical background. Artist statements more specifically serve to connect the field of visual expression and conceptual motivation, allowing the semantic deflection of intent and execution. Multimodal inputs are all preprocessed using standard pipelines such as normalization, tokenization and encoding so that they can be compatible with any learning module. Through shared image modeling, text modeling and metadata modeling, the framework goes beyond single feature analysis and allows a more all-encompassing, context-sensitive modeling of creativity in modern art.
3.3. Feature Extraction Modules (Visual, Semantic, Stylistic, Contextual)
The analytical component of the given creativity measurement framework is extraction of features that convert unstructured multimodal inputs into organized creative features. The modules of visual feature extraction use deep convolutional and transformer based models to learn low and high level visual features such as color distributions, the complexity of texture, composition balance and the novelty of space. These attributes aid in the evaluation of the visual originality and form experimentation. This allows measurement of conceptual richness and interpretive richness in the statements of artists and in the critical texts. Stylistic feature extraction aims at detecting the exceptions in the prescribed artistic styles and movements. Through comparison to reference style clusters, the system assesses stylistic divergence, hybridization and innovation to learned embeddings. The metadata-based contextual features extraction uses historical period, medium and exhibition context as an attribute to extract features in context enabling creativity to be assessed against current norms and constraints. Such contextual cues eliminate the issue of misinterpretation of novelty because they consider the cultural and temporal baselines. The combination of the visual, semantic, stylistic and contextual modules combine to create a multidimensional feature space to represent both perceptual and conceptual creativity. This formalised representation allows strong creativity inference and retains the interpretability and flexibility in a variety of modern artistic works.
4. Experimental Methodology
4.1. Training and evaluation protocols
The proposed AI-based creativity measurement framework should be rigorously tested using the experimental methodology to determine its effectiveness, strength, and generalizability. They start with curated collections of contemporary art in the form of text with descriptions of the artworks and artist statements and contextual metadata. Pictorial data is rescaled and normalized whereas textual information is tokenized, embedded generation and semantics normalized. Stratified sampling is used to evenly divide the dataset into training, validation and test sets in order to maintain diversity in terms of styles, media and artistic movement. Supervised and semi-supervised Model training Model training uses ground truth labels in the form of creativity annotations based on expert ratings or consensus-based scoring. Data augmentation methods (color perturbation and text paraphrasing) are used to improve the robustness of the model and decrease the overfitting. Adaptive gradient-based optimization is done and the early stopping and learning rate scheduling decisions are made based on the validation performance. The evaluation protocols focus on the predictive accuracy as well as interpretability. Figure 2 illustrates hierarchy that promotes training and evaluation of AI creativity testing. The evaluation of stability across splits of data is conducted with the help of cross-validation, whereas the role of particular modalities and feature modules is evaluated with the help of ablation studies.
Figure 2

Figure 2 Architecture for Training and Evaluation Protocols
in AI-Based Creativity Assessment
Experiments are repeated using several random seeds to make sure they are fair. The framework is also assessed on unseen works of art and the cross-domain samples to assess its capacity to extend beyond the training distribution. These procedures provide confident performance evaluation in realistic and different artistic environments.
4.2. Baseline Models and Comparative Setups
In order to prove the benefits of the suggested framework, a variety of base models and comparative configurations are applied. Handcrafted feature models that are based on color histograms, texture descriptors and simple linguistic statistics are traditional statistical baselines upon which linear regression or support vector regression are then performed to score creativity. Unimodal deep learning baselines are vision-only visual novelty assessment models and text-only transformer models of conceptual analysis. These baselines give a benchmark on which the contribution of individual modalities can be evaluated. Comparative systems also encompass hybrid systems with both visual and textual characteristics and late fusion systems with late fusion techniques and the state-of-the-art multimodal vision-language models that are modified to estimate creativity. All baselines are trained and evaluated on the same data subsets and using the same preprocessing conditions, to provide a fair result of the comparison. The performance is assessed in various dimensions of creativity such as novelty, stylistic divergence and conceptual richness. Besides that, ablation-based comparisons entail the selective ablation or substitution of elements of the suggested framework, including contextual metadata or explainability layers.
4.3. Quantitative Evaluation Metrics
To measure creativity quantitatively, it is necessary to have measures that will capture a predictive performance, as well as measures that will reflect the quality of the representation. The standard regression measures, such as the mean absolute error, root mean square error and coefficient of determination, are used to determine the closeness of the predicted creativity scores to the ground truth, annotated by experts. In the case of classification-based tests, accuracy, precision, recall, and F1-score are provided at levels of creativity or category. In addition to traditional measures, creativity-specific measures are included to determine the effectiveness of the models in the process of capturing artistic originality. Novelty indices can be used to measure the extent of deviation between the feature embedding of an artwork and reference distributions as based on historical data. The scores of cross-modal coherence are used to measure the consistency of concepts between visual and textual representations. Interpretability and robustness are measured by explainability-oriented metrics, which are attention entropy and feature attribution stability. Further human expert rating is used to analyze the correlations which further determine the validity of AI-generated creativity measures. Combined, these metrics offer a multiparty and holistic evaluation system to balance between the accuracy of numbers and the artistic significance so that the evaluation of creativity would not be trivial or insignificant.
5. AI Models for Creativity Assessment
5.1. Computer vision models for visual novelty and style analysis
Computer vision models are more important in the evaluation of visual creativity based on formal properties and stylistic disturbances of modern artworks. Convolutional neural networks that are deep are used to obtain hierarchical visual features, which include low-level features like color distributions, edges, and textures, and high-level features such as compositional structures and abstract forms. This analysis is further improved by vision transformers which model long range spatial relations to give sensitivity to global composition, balance and novelty of structure. The visual novelty is estimated by calculating the distances between learned feature embeddings and reference distributions obtained with known works of art, which makes it possible to identify novelty and going against the rule in visual representation. Analysis of style is based on the cluster visual embedding and matching of works of art with stylistic archetypes. This method facilitates the identification of the hybridization, transformation, and the change in style throughout the ages. The process of saliency and attention offers interpretability by identifying areas that help the most in novelty and stylistic variance. Conventional convolutional and transformer-based representations help the computer vision models to adopt both an evocative and experimentative richness about structure. These models are the basis of objective, but flexible analysis of visual creativity that can encompass a variety of artistic media, such as painting, digital art, photography, and mixed-media installations.
5.2. Natural Language Processing Models for Conceptual Depth and Narrative Originality
The models of natural language processing are applied to the evaluation of conceptual and narrative aspect of creativity hidden in text descriptions, artist statements, and critical discourse. Transformer language models produce contextualized embeddings that can be used to model semantic relationships, theme coherence and abstract reasoning with language. Conceptual depth is measured in terms of lexical diversity, metaphor, thematic stratification and complexity of semantics in textual inputs. The originality of the narrative is deduced through divergence of the usual thematic patterns as well as the recognition of distinct conceptual associations. Additional techniques that facilitate the process of identifying new ideas and interdisciplinary references include the use of topic modeling and semantic clustering. Sentiment and discourse analysis are one more aspect of expressive intention and emotional framing, which enhance creativity interpretation. Notably, NLP models can be used to match artistic intent and visual implementation because they help to capture the conceptual inspirations expressed by artists. Attention visualization methods are interpretable since they demonstrate strong phrases and concepts. The models make creativity evaluation not only limited to visual expression, including intellectual and symbolic elements fundamental to modern artistic practice.
5.4. Multimodal and Vision–Language Models for Holistic Creativity Interpretation
Multimodal and vision language models permit global creativity evaluation by symbiotically analyzing the visual and textual data and the single representational space. Vision language architectures represent the interlocking of current creativity through visual novelty, visual style and conceptual narratives. The understanding that comes about through the interpretation of holistic creativity occurs through the assessment of coherence of expression and conceptual intent in visual expression. Cases in which innovative form is supported by original ideas are found. The fusion mechanisms based on attention dynamically combine visual and textual information, and they adapt to various forms of art and presentation conditions. The comparison across artworks by individual or group multimodal models is also possible by providing similarity search and combining creative features. Explainable AI methods contribute to better transparency so that it is possible to trace the score on creativity to a particular visual area and textual object. On the whole, vision-language models are an interpretable and balanced basis of creativity evaluation that combines both perceptual and conceptual levels and does not disregard the complexity of modern art.
6. Results and Analysis
The experimental findings show that multimodal integration is advantageous to AI-based creativity assessment. Models trained vision only had medium accuracy to detect visual novelty and stylistic deviation, but failed to report conceptual intent. Text only models were fine in terms of narrative originality but poor in terms of visual experimentation. Conversely, multimodal vision-language models were always better than unimodal baselines in the extent of their correlation with expert ratings of creativity and cross-modal coherence scores. Ablation experiments established that contextual metadata and artist statements did play off to more balanced creativity interpretation. The focus on visualizations also showed a significant correspondence between meaningful salient visual areas and the important conceptual phrases, which is in line with interpretability. These results suggest that the concept of creativity in modern art can be most effectively described as a multidimensional construct that needs to be analyzed visually, semantically and in context simultaneously.
Table 2
|
Table 2 Comparative Performance of AI Models for Creativity Assessment |
|||
|
Model Type |
Visual Novelty Score (%) |
Conceptual Depth Score (%) |
Cross-Modal Coherence (%) |
|
Handcrafted Features + SVR |
61.4 |
54.7 |
48.2 |
|
CNN-Based Vision Model |
74.8 |
58.3 |
56.9 |
|
Text-Only Transformer Model |
62.1 |
76.5 |
59.4 |
|
Late Fusion (Vision + Text) |
78.6 |
79.2 |
72.8 |
Table 2 has shown a comparative analysis of the various AI models in terms of three main dimensions of creativity: visual novelty, conceptual depth and cross-modal coherence. The support vector regression and handcrafted elements not only score relatively low, at 61.4% and 54.7% in visual novelty and conceptual depth respectively, but also have a low score of 48.2 in cross-modal coherence. Comparison of visual novelty scores in creativity models is presented in Figure 3.
Figure 3

Figure 3 Comparison of Visual Novelty Scores Across
Creativity Model
The results suggest that manually developed descriptors have little ability to represent complicated creative properties in modern art. CNN-based vision model demonstrates a significant increase in visual novelty, with the result of 74.8, indicating its capabilities in the learning of compositional patterns, variation in texture and stylistic variation directly based on images. Comparison of novelty concepts depth, cross-modal coherence between models is presented in Figure 4.
Figure 4
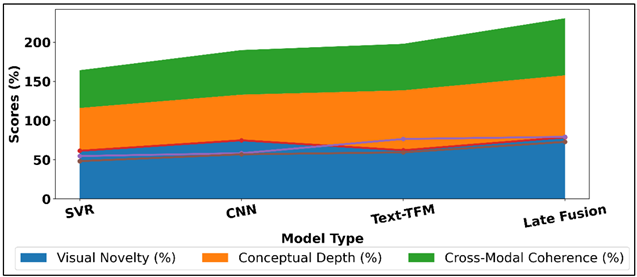
Figure 4 Comparison of Visual Novelty, Conceptual Depth, and
Cross-Modal Coherence Across Models
Nevertheless, its conceptual depth score is only 58.3% showing how even the vision-only models cannot implement abstract concepts or narrative purpose. The conceptual depth evaluation is presented in Figure 5, vision, text, multimodal models. On the other hand, the text-only transformer model is very good at conceptual richness with a high value of 76.5 percent, which is a strong signal of the usefulness of language models in capturing thematic richness and originality as manifested in artist statements and descriptions. The lack of perceptual awareness is proved by its lower visual novelty score of 62.1%.
Figure 5

Figure 5 Conceptual Depth Evaluation for Vision, Text, and
Multimodal Models
This is because of the highest balance, visual novelty at 78.6, conceptual depth at 79.2, and a much greater cross-modal coherence of 72.8 with the late fusion model that integrates vision and text. The enhancement of this indicates that multimodal integration can play a significant role in assessing holistic creativity in which perception and conceptual originality play along with each other.
7. Conclusion
In this paper, the authors have developed an extensive AI-based approach to creativity measurement in modern art through the combination of computer vision, natural language processing, and multimodal learning. To overcome the shortcomings of old-fashioned qualitative analysis and separate quantitative indicators, the suggested method frames creativity as a multidimensional construct that contains the visual novelty, stylistic departure, conceptual richness, narrative originality and contextual relevance. Through the collective analysis of artworks, artist statements and metadata, the framework offers scalable, reproducible and explicable indicators of creativity which may be used to complement human judgment and not substitute it. The experiment analysis shows the obvious superiority of multimodal and vision-language frameworks to unimodal ones. Findings indicate better consistency with the expert ratings, greater generalization between different artistic images, and a better interpretability of the data with the help of the attention-based explanations. These results serve to affirm that creativity in modern day art cannot be well-defined by visual representation or textual purpose but rather comes out of the process of the perception, concept, and context. The fact that explainable AI elements can be included also enhances the relevance of the framework to the art criticism, curation, and education fields, since the assessment through algorithms becomes transparent and responsible. Other than its benefits in terms of performance, the study has a conceptual contribution, which is operationalizing creativity in a way that validates artistic richness and at the same time allows computational analysis. It is practically useful to digital archives, web-based exhibits and web-based art education platforms, as well as large scale cultural analytics, where comparative and systematic assessment is becoming more and more a requirement. Nonetheless, such ethical aspects as cultural bias, data presentation, and excessive dependence on numerical scores should be thoroughly handled.
CONFLICT OF INTERESTS
None.
ACKNOWLEDGMENTS
None.
REFERENCES
Borji, A. (2023). Generated Faces in the Wild: Quantitative Comparison of Stable Diffusion, Midjourney and DALL·E 2 [Preprint]. arXiv.
Cheng, M. (2022). The Creativity of Artificial Intelligence in art. Proceedings, 81, Article 110. https://doi.org/10.3390/proceedings2022081110
Giannini, T., and Bowen, J. P. (2023). Generative Art and Computational Imagination: Integrating Poetry and Art. In Proceedings of EVA London 2023 (211–219). https://doi.org/10.14236/ewic/EVA2023.37
Guo, D. H., Chen, H. X., Wu, R. L., and Wang, Y. G. (2023). AIGC Challenges and Opportunities Related to Public Safety: A Case Study of ChatGPT. Journal of Safety Science and Resilience, 4(4), 329–339. https://doi.org/10.1016/j.jnlssr.2023.08.001
Horton, C. B., Jr., White, M. W., and Iyengar, S. S. (2023). Bias Against AI Art can Enhance Perceptions of Human Creativity. Scientific Reports, 13, Article 19001. https://doi.org/10.1038/s41598-023-45202-3
Kannen, N., Ahmad, A., Andreetto, M., Prabhakaran, V., Prabhu, U., Dieng, A. B., and Bhattacharyya, P. (2024). Beyond Aesthetics: Cultural Competence in Text-to-Image Models [Preprint]. arXiv.
Leong, W. Y., and Zhang, J. B. (2025). AI on Academic Integrity and Plagiarism Detection. ASM Science Journal, 20, Article 75. https://doi.org/10.32802/asmscj.2025.1918
Leong, W. Y., and Zhang, J. B. (2025). Ethical Design of AI for Education and Learning Systems. ASM Science Journal, 20, 1–9. https://doi.org/10.32802/asmscj.2025.1917
Liu, B., Wang, L., Lyu, C., Zhang, Y., Su, J., and Shi, S. (2024). On the Cultural Gap in Text-to-Image Generation. Frontiers in Artificial Intelligence and Applications, 392, 930–937. https://doi.org/10.3233/FAIA240581
Lou, Y. Q. (2023). Human Creativity in the AIGC Era. Journal of Design Economics and Innovation, 9(4), 541–552. https://doi.org/10.1016/j.sheji.2024.02.002
Marcus, G., Davis, E., and Aaronson, S. (2022). A Very
Preliminary Analysis of DALL·E 2 [Preprint].
arXiv.
Rhem, J. A. (2023). Ethical use of Data in AI Applications. IntechOpen.
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. (2022). High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) ( 10684–10695). https://doi.org/10.1109/CVPR52688.2022.01042
Santoni de Sio, F. (2024). Artificial Intelligence and the Future of Work: Mapping the Ethical Issues. Journal of Ethics, 28(4), 407–427. https://doi.org/10.1007/s10892-024-09493-6
Shao, L. J., Chen, B. S., Zhang, Z. Q., Zhang, Z., and Chen, X. R. (2024). Artificial Intelligence Generated Content (AIGC) in Medicine: A Narrative Review. Mathematical Biosciences and Engineering, 21(2), 1672–1711. https://doi.org/10.3934/mbe.2024073
Wei, M., Feng, Y., Chen, C., Luo, P., Zuo, C., and Meng, L. (2024). Unveiling Public Perception of AI Ethics: An Exploration on Wikipedia Data. EPJ Data Science, 13, Article 26. https://doi.org/10.1140/epjds/s13688-024-00462-5
Westermann, C., and Gupta, T. (2023). Turning Queries into Questions: For a Plurality of Perspectives in the Age of AI and Other Frameworks with Limited (mind)Sets. Technoetic Arts: A Journal of Speculative Research, 21(1), 3–13. https://doi.org/10.1386/tear_00106_2
|
|
 This work is licensed under a: Creative Commons Attribution 4.0 International License
This work is licensed under a: Creative Commons Attribution 4.0 International License
© ShodhKosh 2025. All Rights Reserved.