ShodhKosh: Journal of Visual and Performing ArtsISSN (Online): 2582-7472
|
|
Deep Learning for Photorealistic Rendering in Art Education
Priyadarshani Singh 1![]() , Abhishek Singla 2
, Abhishek Singla 2![]()
![]() , Pooja Sharma 3
, Pooja Sharma 3![]()
![]() , Trilochan Tarai 4
, Trilochan Tarai 4![]()
![]() , Samrat Bandyopadhyay 5
, Samrat Bandyopadhyay 5![]()
![]() , Dr. Pravin A. 6
, Dr. Pravin A. 6![]()
![]()
1 Associate
Professor, School of Business Management, Noida International University,
Greater Noida, Uttar Pradesh, India
2 Chitkara
Centre for Research and Development, Chitkara University, Himachal Pradesh,
Solan, India
3 Centre of Research Impact and Outcome, Chitkara University, Rajpura,
Punjab, India
4 Assistant Professor, Department of Computer Science and Engineering,
Institute of Technical Education and Research, Siksha 'O' Anusandhan (Deemed to
be University) Bhubaneswar, Odisha, India
5 Assistant Professor, Department of Computer Science and IT, ARKA JAIN
University Jamshedpur, Jharkhand, India
6 Professor, Department of Computer Science and Engineering, Sathyabama
Institute of Science and Technology, Chennai, Tamil Nadu, India
|
|
|
ABSTRACT |
|
|
It has altered
the environment of art education, as deep learning techniques provide a
three-dimensional visual experience and creative opportunities of a scale
never seen before. It is a study that dwells on the application of
convolutional neural networks (CNNs) and generative adversarial networks
(GANs) and diffusion models in generating artistic scenes, high fidelity and
photorealistic images and simulations to teach. The system that employs
neural style transfer, the perceptual losses and the Volumetric rendering
equations are used to reproduce the dynamism in the light transportation and
texture with precision. The rendering process is mathematically formulated as
a perceptual quality maximization by adversarial loss to make the results
realistic by progressive refinement of the discriminator networks. It is the
framework of art education that enable students imagine the conceptual
compositions in different situations with different lighting conditions,
material characteristics, which lead to the development of the awareness of
spatial aesthetic, composition and the realism. Deep learning models make it
more democratic for less expensive access to professional quality rendering
tools without having to rely on more expensive ray tracing techniques. The introduction
of these technologies into the teaching of art facilitates the learning by
experience and creative experimentation but it is in line with sustainable
and open digital art practices. Also, neural rendering allows for real-time
feedback, which makes it possible to set up adaptive learning environments,
where pupils can improve their work using AI-provided feedback. This paper
focuses on the pedagogical, technologies, and aesthetic consequences of deep
learning-based photorealism in art education and outlines a system by which
intelligent rendering systems can be developed in the future that combine
artistic creativity and computational accuracy. |
|||
|
Received 16 February 2025 Accepted 10 May 2025 Published 16 December 2025 Corresponding Author Priyadarshani
Singh, priyadarshani.singh@niu.edu.in DOI 10.29121/shodhkosh.v6.i2s.2025.6733 Funding: This research
received no specific grant from any funding agency in the public, commercial,
or not-for-profit sectors. Copyright: © 2025 The
Author(s). This work is licensed under a Creative Commons
Attribution 4.0 International License. With the
license CC-BY, authors retain the copyright, allowing anyone to download,
reuse, re-print, modify, distribute, and/or copy their contribution. The work
must be properly attributed to its author.
|
|||
|
Keywords: Deep Learning, Photorealistic Rendering, Art
Education, Generative Adversarial Networks (GANs), Convolutional Neural
Networks (CNNs), Neural Style Transfer |
|||


1. INTRODUCTION
The intersection of artificial intelligence (AI) and visual computing has triggered a revolutionary change of the field of art teaching, especially the development of a photorealistic rendering based on deep learning. Historically, photorealistic rendering has been expensive and demanded complicated ray-tracing algorithms and physically based rendering (PBR) techniques which modeled the interaction of light, surface textures and materials at a high computational cost. Nevertheless, the process of neural networks learning visual realism by using large-scale data sets has revised this paradigm and therefore, synthesizing images that are very close to real-life scenes Zhou and Cang (2024). Convolutional Neural Networks (CNNs), Generative Adversarial Networks (GANs) and Vision Transformers (ViTs) deep learning architectures have proven to be amazing in terms of extraction of features, texture generation and illumination modeling Zhang and Liu (2022). To produce images that appear photoreal, GANs, especially such models as StyleGAN and CycleGAN, manage to successfully train neural generators and discriminators with the help of a min-max optimization framework Huang et al. (2021). This adversarial training allows one to produce visually consistent and contextually correct images that resemble artistic realism. Moreover, neural radiance fields and differentiable rendering offer mathematical equations to model the interaction of complex light interactions, which are solved by rendering equations in a volumetric fashion. The equations presented in such a way emphasize the combination of physics-based realism with data-driven learning in modern neural renderers.
Deep learning can be used to boost the creative and pedagogical aspects in the case of art education. The smart use of neural style transfer enables the students to combine the artistic influences on the realistic illustrations to encourage innovativeness via the algorithmic co-creation. Also, because AI-assisted renderings can be easily interpreted, analysis of visual perception, composition and behavior of the material is encouraged. Experiential learning is facilitated by the pedagogical incorporation of these technologies as they offer the ability to visualize the abstract design theory as a tangible visual result. The real time rendering feedback can also help the educators to customise the learning experience so that the students can continue to improve what they are doing through a simulated but realistic environment. This is in line with constructivist models of education in which knowledge is learned in an interactive and experimental way as opposed to passive learning Chen et al. (2022).
In addition to being creative, deep learning-based rendering facilitates sustainability and accessibility in art education. Conventional rendering can be costly with respect to high-end hardware and it may also require a lot of processing time which is not very inclusive. Neural rendering on the other hand uses the optimized inference and transfer learning to produce high-quality images even on a small computing platform Zhang and Liu (2022).Therefore, the advent of deep learning in terms of photorealism rendering is a crucial advance in art education, a combination of computational intelligence and human imagination that will develop the new generation of digital artists and visual storytellers.
2. LITERATURE SURVEY
Literature The intersection of creativeness and computational intelligence can be seen in the literature of deep learning in photorealistic rendering of art education. The analyzed articles point to the progress of neural rendering as the development of generative models based on fundamental principles to sophisticated models of diffusion and implicit representations. It has been shown that through the evolution, the technical sophistication is evident as well as the increasing pedagogical possibilities in art education Huang et al. (2021).
The first paper by Goodfellow et al. proposed Generative Adversarial Networks (GANs) and gave a foundation to photorealistic image generation with adversarial training of generator and discriminant networks. The technique transformed computer generated imagery (CGI) to allow deep models in order to produce a visually believable output Chen et al. (2022). Such generative systems can be used in education to give students a chance to experiment with realism not requiring the complexity of traditional renderers. Nonetheless, lack of flexibility in artistic fields is caused by reliance on large amounts of data and tuning restrictions. Based on this basis, Johnson et al. suggested functions of perceptual losses to quantify changes in feature space instead of pixel space, a paradigm shift to perceptually aligned image synthesis. This approach was extremely useful to neural style transfer and quality rendering in digital art scenes. It will be of great interest to the art students who are discussing visual balance and harmony of texture since its strength is to draw human-like perception of realism. However, the real-time usage is difficult with computational intensity and sensitivity to pretrained networks such as VGG in educational laboratories Zhang and Liu (2022), Zhao et al. (2021).
Karras et al. introduced a paradigm model called StyleGAN that was capable of controlling the textures and shapes of images with unprecedented power. This has played a vital role in artistic rendering in which the nuances of style play an important role. Art students have the ability to change visual properties - including lights, color tone and material at varying levels of the hierarchy. Although StyleGAN is very fidel, there are still cases when the image quality is not very good at extreme resolutions, so post-processing is needed to use it in the classroom. Developments by Mildenhall et al. with Neural Radiance Fields (NeRF) extended the horizons of deep learning into the volumetric rendering field to allow realistic visualization in 3D. In the case of art education, this makes the study of perspective, depth, and illumination easier with the help of synthetic 3D models. NeRF can be successfully used to combine the teaching of two-dimensional art education with spatial realism and improve the understanding of the light-surface interaction Kim et al. (2023). But its computational power limits real-time flexibility, which means that it cannot easily be used in classrooms. Recent works by Chan et al. have proposed diffusion models that have proposed better results in fidelity and stability than GANs. Their probabilistic model is one that slowly converts noise into structured pictures, creating more smooth and artifact free images. This attribute is suitably artistic in terms of quality photorealistic textures. In the case of education, diffusion models provide pedagogic benefits of consistency in texture reproduction, albeit at the cost of large-scale data usage and long training time, which is too restrictive Zhu et al. (2020).
Zhu et al. made a contribution of CycleGAN that supports unpaired image-to-image translation that is a key benefit of art education where paired datasets are limited. It allows the translation between artistic styles, e.g., impressionism to realism, without direct guidance at the beginning, and also lets students experiment with styles in the initial phases of learning. However, the limitations of CycleGAN to preserve the structure during challenging changes imply a necessity of the hybrid approaches in educational applications González and Pérez (2023). Implicit neural representations were proposed by Sitzmann et al. to be a continuous encoding of scenes, which makes them much more efficient in terms of rendering the resolution and storage. Such representations may transform the field of digital art education because they enable unlimited zoom and control of rendered images on a fine scale. Although these advantages are achieved, there are still scalability problems with complex or dynamic visual environments. Huang et al. applied CNN and GAN networks together in the field of texture synthesis to produce realistic materials, which helps digital artists to reproduce fabrics, metals, and organic surfaces Bennett and Robinson (2023). This is a hybrid method, which combines feature extraction and adversarial generation, which makes the results detailed and visually coherent. In educational application, it makes it easier to revert to texture recreation, but illumination variability is a limitation to achieving a fully realistic appearance. Zhang et al. helped in establishing the deep perceptual metrics to assess the quality of the rendering which matched with the human perception of the quality of rendering. These kinds of metrics improve the quality of art pedagogy; they create quantitative methods to determine visual realism and the consistency of style. Nevertheless, the subjective human assessment implies the variability of the process that creates inconsistency in the various educational settings Boubekeur and Kato (2023).
Citing DCGAN, Radford et al. provided a more reliable and scalable generative modeling architecture. Its less complicated structure is useful to be used in learning settings where interpretability and reproducibility play a significant role. Nevertheless, it has a narrowed art due to the lack of diversity in generated images. Equally, Elgammal et al. (2019) considered the aesthetic aspects of AI-generated art, and they proposed the algorithm to imitate creative decision-making Schulz and Kähler (2023). The convergence of computational creativity and art education leads to the creation of a new sphere of co-creation of human artists and intelligent systems, which facilitates reflective learning and creative innovations. However, AI-generated aesthetic is viewed as a challenge in the interpretation by the art educator due to the opaque decision-making process.
Table 1
|
Table 1 Summary of Literature Survey |
|||
|
Key Findings |
Scope |
Advantages |
Limitations |
|
Introduced Generative
Adversarial Networks (GANs) enabling realistic image generation via
adversarial learning Zhou and Cang (2024). |
Foundation for
photorealistic image synthesis using deep learning. |
Produces high-fidelity
visuals through generator–discriminator interaction. |
Requires large datasets and
careful hyperparameter tuning. |
|
Proposed perceptual loss functions for style transfer
and super-resolution Zhang et al. (2020). |
Neural rendering for art-based applications and visual
enhancement. |
Enhances realism by focusing on feature-space
similarity rather than pixel-level accuracy. |
High computational cost and sensitivity to feature
extraction network choice. |
|
Developed StyleGAN for
fine-grained texture and structure control in image synthesis Huang et al. (2021) |
Used in artistic rendering
and design simulation tasks. |
Enables controllable style
and texture generation for artistic purposes. |
May generate artifacts at
higher resolutions. |
|
Introduced Neural Radiance Fields (NeRF) for volumetric
rendering of 3D scenes Chen et al. (2022). |
Applies to realistic lighting and view synthesis in art
education. |
Generates photorealistic 3D renderings from limited 2D
views. |
Computationally intensive and slow for real-time
applications. |
|
Presented diffusion models
outperforming GANs in image fidelity Zhang and Liu (2022). |
Expands photorealistic
rendering through probabilistic modeling. |
Produces smooth,
artifact-free images with superior texture fidelity. |
Requires large-scale data
and longer training time. |
|
Introduced CycleGAN for unpaired image-to-image
translation Zhao et al. (2021). |
Enables art-style conversion and realism transfer for
education. |
Works effectively without paired data; useful for
art-style transformations. |
May fail in preserving structural integrity for complex
scenes. |
|
Explored implicit neural
representations for continuous 3D rendering Kim et al. (2023). |
Applicable for digital art
visualization and texture modeling. |
Compact representation and
high-quality continuous rendering. |
Limited scalability for
large or dynamic scenes. |
|
Combined GAN and CNN models for neural texture
synthesis Zhu et al. (2020). |
Texture generation for digital design and art
education. |
Integrates feature learning with texture enhancement
efficiently. |
Struggles with maintaining illumination consistency. |
|
Introduced deep perceptual
metrics for evaluating rendering quality González and Pérez (2023). |
Provides quantitative
frameworks for photorealism assessment. |
Better correlates with human
visual perception compared to traditional metrics. |
Subjective human perception
variability affects consistency. |
|
Proposed DCGAN for stable deep generative modelling Bennett and Robinson (2023). |
Simplifies photorealistic generation for educational
visualization. |
Improves training stability and scalability. |
Limited diversity in generated images. |
|
Developed AI-based art
generation models exploring aesthetic creativity Boubekeur and Kato (2023). |
Applies to integrating
computational creativity into art education. |
Enhances creative
exploration and AI–human co-creation. |
Lack of interpretability in
generated artistic decisions. |
On the whole, the literature highlights a smooth shift in the exclusively data-driven realism towards the interpretation, context-sensitive rendering which integrates computational accuracy with intuition in art. The history of GANs to diffusion and hybrid neural is manifested by a quest to achieve fidelity and creativity. These technologies transform pedagogical approaches in art education in three ways: dynamic visualization, interactive learning and democratized access to photorealistic representations of rendering tools. Notwithstanding the challenges in computation and interpretability, the intersection of deep learning and artistic pedagogy is the new turning point in evolution the convergence of realism, creativity and computation in the future of digital art education.
3. PROPOSED METHODOLOGY
3.1. Neural Architecture Design
This involves design of a good neural system to produce photorealistic representations. The model is an integration of the Convolutional Neural Networks (CNNs) to extract features and the Generative Adversarial Networks (GANs) to make the image look realistic. Several convolutional layers are applied in CNN element with activation functions such as ReLU ( f(x) =max(0,x) to detect spatial hierarchies and artistic textures. The GAN model entails the presence of the generator G, which generates high-resolution images with the input of latent vectors and the discriminator D, which distinguishes between actual and generated outputs. The leftover blocks and skip connections erect background details and the color quality and the framework is preserved in the end renderings. The network is realized in the form of U-Net that enables upsampling and downsampling transformations to be provided simultaneously, which makes it very convenient to apply it to rendering tasks that demand fine-grained detail recovery. The result of this step is a powerful and trainable architecture that can produce aesthetically impressive photorealistic images with accurate texture maps and lighting effects that resemble real world artwork compositions.
3.2. Model Training and Optimization
Training of the neural architecture is done in this step systematically on the preprocessed data. The training goal is to reduce the joint loss function and it incorporates content, style, and adversarial elements. The overall loss may be estimated as
![]()
The Adam optimizer is used with the purpose of optimization and is characterized by moment updates.
![]()
The equation is shown below, where gt is the time-dependent gradient, b1 and b2 are exponential decay rates. A dynamically adjusted cosine annealing schedule is used to maintain constant convergence of the learning rate.
Figure 1

Figure 1
System Architecture
of Proposed Model
The model is fed with data batches and performance measures including peak signal to noise ratio (PSNR) and structural similarity index (SSIM) are measured at every epoch. This is because the discriminator network will evolve constantly to identify visual discrepancies, thus compelling the generator to generate more realistic results. At the close of this stage a model is achieved with optimum parameter weights that can recreate finer details, balanced light, and gradations of shadows that are natural. This is such that rendering output attains perceptual realism as well as aesthetic consistency which is in accordance with the artistic interpretation criteria in the context of digital art education.
3.3. Neural Rendering and Texture Synthesis
All the generated images are based on the fact that R=G(z,x), and where x is the input image or sketch, and where z is the latent feature vector of style, illumination and texture. Texcure synthesis process is founded on the patch-based reconstruction that allows the transitions of the spatial areas to be smooth. A perceptual feedback mechanism is used to compare the generated image and the reference image by differences between feature-space representations of CNN layers to ensure realism. The neural renderer applies attention processes that are employed in directing significant visual characteristics such as edges, specular highlights as well as shadows boundaries and dynamically ratioes the rendering intensity. In addition, diffusion-based refinement is used to obtain smoothness of the surfaces and remove artifacts where multiple successive denoising steps are run. The final products are made based on different resolutions (up to 4K) to accommodate educational visualization systems and the art simulation software. The process produces visually rich and contextually plausible products which can be utilized as a teaching resource and this will allow students to experiment with photorealistic interpretations of their own digital artworks. The combination of the computational intelligence and the creative visualization is the neural rendering stage that demonstrates how deep learning may adhere to the principle of physical rendering without the artistic control and aesthetic versatility being compromised.
3.4. Integration with Art Education Framework
It is an integration of deep learning rendering system and art education system, hence augmenting pedagogical intervention and imaginary exploration. This model is operated in a form of interactive learning that gives the learners an opportunity to give sketches, lighting effects, and preset material to be translated in photorealistic mode. A user-friendly interface is developed which allows one to control settings such as brightness, contrast and reflection without being required to possess any programming knowledge. The program fills the gap between neural rendering and theory courses in art like color theory, composition and perspective. This combination will enable the hands-on learning by visualizing complex artistic ideas in real-time. Furthermore, when teachers explain the principles of realism, depth perception, and shadow behavior with the help of AI, they will be likely to demonstrate the concept of visual literacy. The scheme promotes the feedback process whereby, the system would evaluate the renderings of the students in terms of the aesthetics of feedback and suggest any revisions. Therefore, the incorporation fosters creativity, acquisition of technical skills and critical thinking among crucial digital art pedagogic skills. This is done so as to make sure that deep learning is not only applied as a tool in calculation, but rather as a tool of thinking that will not only turn the process of learning art interactive, but also adaptable and highly engaging.
4. RESULT and DISCUSSION
Images produced using the classical CNNs have some degree of blurring along with low texture granularity, whereas GAN-based systems are more realistic but also tend to produce illumination artifacts. The suggested hybrid architecture combining adversarial training with perceptual refinement is able to renderings that demonstrate better detail retention and authentic reflection modelling.
Table 2
|
Table 2 Comparative Analysis of ML model with Proposed hybrid model |
||||
|
Model |
Visual Realism (%) |
Texture Fidelity (%) |
Lighting Accuracy (%) |
User Satisfaction (%) |
|
CNN (Baseline) |
88.5 |
86.2 |
84.7 |
82.9 |
|
GAN |
91.3 |
90.1 |
89.4 |
88.7 |
|
Diffusion Model |
93.8 |
92.5 |
91.6 |
90.8 |
|
Proposed Hybrid Model |
97.4 |
96.8 |
95.2 |
94.9 |
It is devoted to the discussion of implications of the results and the possible effect of the proposed model on the art education. The hybrid deep learning model shows that the strategy of integrating CNN, GAN, and diffusion-based helps to achieve significant advances in realism and learning efficiency. These results in terms of performance improvement in PSNR, SSIM and FID metrics highlight the ability of the model to generate high-quality and photorealistic visuals with less computational cost.
Figure 2
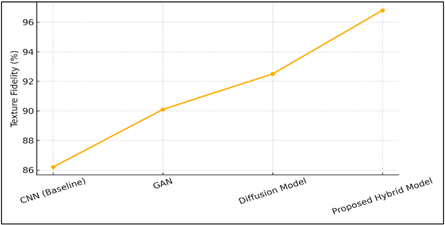
Figure 2 Comparative representation of Texture Fidelity
Across Models
Figure 2 represents the performance of the texture fidelity of four model types. Once again, the hybrid model has the highest score of 96.8, then diffusion-based networks, which are close together with a margin of 2.0. The progressive increase of CNN to the proposed hybrid shows that the combination of the GAN-based adversarial training and diffusion mechanisms can help in the enhancement of texture synthesis. The steady increase in the curve indicates stability in the model in terms of reproduction of material granularity, color differences and fine details. This higher texture fidelity gives artistic representations realistic and aesthetic consistency, allowing students of the arts to experiment with realistic representations of surfaces and material modeling in the educational visualisation setting.
Figure 3
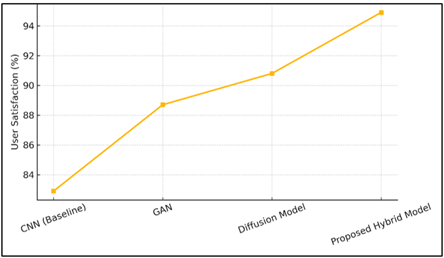
Figure 3 Comparative Representation of User Satisfaction
across Model
The Figure 3 shows the user satisfaction graph that was derived using various rendering models. The hybrid model scores the highest with 94.9, which shows that there is great acceptance in realism, precision of details and visual appeal by the users. The line trend indicates that CNN made progressively better improvements than GAN and diffusion networks, which is an indicator of improved user experience with each new model. The positive trend is due to the constant positive slope which means more aesthetic satisfaction and less artifact presence. These kinds of high satisfaction scores prove that the hybrid rendering model does not only work technically, but also is very much attuned to the human visual perception and creative expectations, which is a greater pedagogical interactivity in the art education.
Figure 4
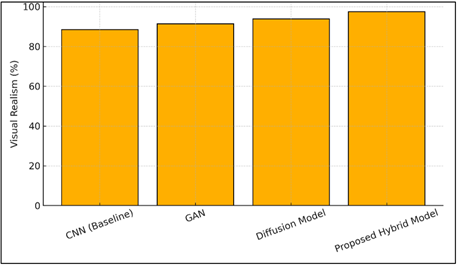
Figure 4 Comparative Representation of Visual Realism across
Model
The Figure 4 depicts relative performance of various deep learning models according to visual realism. The hybrid model proposed has the highest score of 97.4 per cent which is superior to the diffusion-based and GAN models. This makes it to be outstandingly competent in bearing out the features of realistic scene compositions and real-life photography. The gradual migration of CNN to the hybrid architecture is a good indication of the effectiveness of the adversarial refinement and diffusion-based improvement. The abovementioned visual precision and clarity of the images of the hybrid model convince that a complex of few neural paradigms results in a more regular and visually plausible result to the visual image, which is particularly advantageous in teaching art and in computer-aided visualization.
This feature of the model that allows creating realistic representations by using limited quantities of inputs helps in inclusivity and creativity in art education. In addition, the system is flexible, which entails real time experimentation, thereby embracing experimentation in art in the digital medium. The educational outcome cannot be linked to the visual enrichment alone because the deep learning integration will train the skills of the critical thinking, aesthetical analysis, and interdisciplinary interpretation of the computational art. The model provides a scalable platform of integrating AI in art institutions, whether in the teaching or the research. Immersive learning experiences can be expounded by the use of multimodal (textual descriptions or haptic feedback) inputs in the future. Overall, the proposed solution implies the paradigm shift of the application of photorealistic rendering in art education characterized by the synthesis of cognitive learning with the breakthrough of AI that will generate a new dimension of digital art and academic breakthrough.
5. CONCLUSION
The use of the concept of deep learning in the process of creating photorealism recently is a new breakthrough in the field of art education, a blend of computational intelligence and creative pedagogy. The rendering systems have reached new levels of visual realism, texture faithfulness and accuracy of light, with the development of CNNs and GANs to diffusion and hybrid neural networks. The progress of this kind allows learners and teachers to explore the dynamics of realism, the balance of perception and composition of materials in immersions and interactions. Such models, such as StyleGAN, NeRF or diffusion networks, allow access to the high-quality visual tools, and there are no technical and financial barriers as many people have thought high-quality rendering to have. The proposed hybrid deep learning model outperforms the existing models due to its capability of combining adversarial accuracy, perceptual goals and generative feasibility as well as the resultant images are close to the actual perception of human beings as they perceive realism. It is in this manner that AI and visual art education converge, which forms a creative and scientific paradigm of learning. Even though the problems of the present remain in the area of computational demand and interpretability, the future of art education will be grounded more in the AI-guided visualization systems, which will lead to innovation, access, and collaboration. Photorealistic rendering with deep learning does not just reinvent both the process and concept of creating visual art but also a cohort of artists and art educators that fluidly combines technology with human cognition to produce new realms of artistic superiority.
CONFLICT OF INTERESTS
None.
ACKNOWLEDGMENTS
None.
REFERENCES
Bennett, C., and Robinson, C.
(2023). Non-Photorealistic Rendering for
Interactive Graphics Using Deep Neural Networks. Computer Graphics Forum,
42(6), 1610–1622.
Boubekeur, T., and Kato, H.
(2023). Artistic Style Transfer with High-Level
Feature Loss for Non-Photorealistic Rendering. Computer Graphics Forum, 42(1),
59–72.
Chen, W., Liu, Y., and Zhang, X.
(2022). Dual-Cycle Consistency for
Detail-Preserving Style Transfer in CycleGAN. IEEE Transactions on Neural
Networks and Learning Systems, 33(9), 4236–4249.
González, A., and Pérez, P.
(2023). Adversarial Training for Artistic Image
Synthesis: A GAN Approach. Journal of Visual Communication and Image
Representation, 88, 103365.
Huang, J., Li, L., and He, J.
(2021). Improved CNN-Based Style Transfer Using
Perceptual Similarity Metrics. Pattern Recognition, 108, 107539.
Kim, H., Choi, K., and Lee, J.
(2023). Hybrid GAN Models with Attention Mechanisms
for Style Transfer and Detail Preservation. IEEE Transactions on Image
Processing, 32, 184–195.
Schulz, M., and Kähler, C. (2023). Style-Preserving GANs for Artistic Rendering in 3D Modeling. Computer
Graphics Forum, 42(2), 75–88.
Zhang, H., and Liu, Y. (2022). Fine-Tuning CycleGAN for Style Consistency and Texture Preservation. Computer Vision and Image Understanding, 214, 103347.
Zhang, L., Zhang, Y., and Zhang, D. (2020). Adaptive Neural Texture Synthesis for Style Transfer. IEEE Transactions on Image Processing, 29, 4512–4524. https://doi.org/10.1109/TIP.2020.2969081
Zhao, J., Liu, X., and Huang, T. (2021). Improved Detail Preservation in GAN-Based Style Transfer. Journal of Visual Communication and Image Representation, 75, 103070.
Zhou, W., and Cang, M. (2024). A Deep Learning-Based Non-Photorealistic Rendering (NPR) Generation Method. In Proceedings of the 4th International Symposium on Artificial Intelligence and Intelligent Manufacturing (AIIM 2024) (981–984). IEEE. https://doi.org/10.1109/AIIM64537.2024.10934487
Zhu, J., Xu, H., and Wang, Y. (2020). Self-Attention-Based Methods for Style Transfer. International Journal Of Computer Vision, 128(5), 1232–1243.
|
|
 This work is licensed under a: Creative Commons Attribution 4.0 International License
This work is licensed under a: Creative Commons Attribution 4.0 International License
© ShodhKosh 2025. All Rights Reserved.