ShodhKosh: Journal of Visual and Performing ArtsISSN (Online): 2582-7472
|
|
Generative Art Photography Using Diffusion Models
Nidhi Tewatia 1![]() , Lalit Khanna 2
, Lalit Khanna 2![]()
![]() , Dr. Jeberson Retna Raj 3
, Dr. Jeberson Retna Raj 3![]()
![]() , Pavas Saini 4
, Pavas Saini 4![]()
![]() , Dr. Kunal Meher 5
, Dr. Kunal Meher 5![]()
![]() , Dr. Bichitrananda Patra 6
, Dr. Bichitrananda Patra 6![]()
![]()
1 Assistant
Professor, School of Business Management, Noida international University, India
2 Chitkara
Centre for Research and Development, Chitkara University, Himachal Pradesh,
Solan, India
3
Professor, Department of Computer Science and
Engineering, Sathyabama Institute of Science and Technology, Chennai, Tamil
Nadu, India
4 Centre of Research Impact and Outcome, Chitkara University, Rajpura,
Punjab, India
5 Assistant Professor, UGDX School of
Technogy, ATLAS Skill Tech University, Mumbai, Maharashtra, India
6 Professor, Department of Computer Applications, Institute of Technical Education and Research, Siksha 'O' Anusandhan (Deemed to be University) Bhubaneswar, Odisha, India
|
|
|
ABSTRACT |
|
|
This work
introduces a hybrid diffusion model with the purpose of improving generative
art photography via the combination of latent space denoising, dual guidance
and photography-aware conditioning. By using text-based semantic control in
conjunction with exposure, depth-of-field and color harmonic cues, the system
generates more aesthetically consistent images that are more photographically
realistic. Experimental results demonstrate that the proposed model has
higher visual clarity, more aligned prompt, and more stable light compared to
baseline diffusion frameworks, and only needs much fewer sampling steps with
the help of auxiliary consistency refinement module. Further analyses like
distribution of the aesthetic score, exposure heatmaps, structural-creativity
trade-off, and sharpness of texture comparisons verify the validity of the
model. |
|||
|
Received 16 January 2025 Accepted 08 April 2025 Published 10 December 2025 Corresponding Author Nidhi
Tewatia, nidhi.tewatia@niu.edu.in
DOI 10.29121/shodhkosh.v6.i1s.2025.6645 Funding: This research
received no specific grant from any funding agency in the public, commercial,
or not-for-profit sectors. Copyright: © 2025 The
Author(s). This work is licensed under a Creative Commons
Attribution 4.0 International License. With the
license CC-BY, authors retain the copyright, allowing anyone to download,
reuse, re-print, modify, distribute, and/or copy their contribution. The work
must be properly attributed to its author.
|
|||
|
Keywords: Diffusion Models, Hybrid Diffusion Architecture,
Generative Art Photography, Latent Denoising, Prompt Guidance,
Photography-Aware Conditioning |
|||


1. INTRODUCTION
Generative art photography represents a silent revolution in the process by which images are created, moving the act of creation away from minimizing light passing through a lens, and instead creating form from mathematical noise. Instead of relying on a physical camera Rombach et al. (2023), diffusion models are learned to create images from a process of gradual refinement, which starts from a cloud of randomness and ends with images that are visually coherent. This movement makes the photographic act closer to the art of dream-making, in which prompts, semantic embeddings and noise schedules replace aperture, shutter speed and focal length as tools at the disposal of the artist Ruiz et al. (2023). Diffusion models work off of a very simple but very powerful concept: Starting with pure noise, then de-noise bit by bit until you are left with a meaningful image. Each iteration of excluding background noise may be good seen as a gentle stroke of the brush made under the control of a neural network trained by analyzing millions of visual examples. As the steps are taken, shapes become sharper, the lighting becomes more stable, the color tones become harmonious, and the semantic structure can be seen Song et al. (2021). The process is similar to watching a darkroom print come into clarity except in place of the chemistry there is probability.
Figure 1
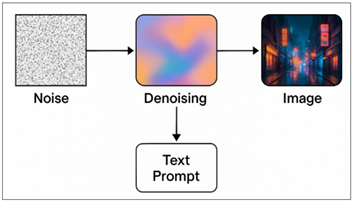
Figure 1 Basic Block Schematic of diffusion-based generative
art photography
What makes diffusion models especially suitable for generative photography is that they are controllable as shown in Figure 1. Through text prompts, the model can be guided by the artist towards particular styles, moods, compositions or subjects Huang et al. (2024). A prompt like "soft cinematic portrait lit by the golden hour sunlight" is sufficient to prompt the model to recreate the whole look of it - everything from lens behavior to color palette - based entirely on acquired priors. With image-to-image techniques, creators can remix or reimagine already existing photographs, adding surreal textures, changing the composition or stretching the frame in ways that traditional cameras could never achieve Yang et al. (2023).
Generative art photography is also an art form that combines craft and computation Wang et al. (2023). "The artist becomes a conductor who is directing a complex orchestra of model parameters: sampler types are used to control rhythm, classifier-free guidance adjusts adherence and seeds control alternate visual branches of the same conceptual world Wang et al. (2023)." These choices go into the final image as decisively as the real world photographers choose their lenses, filters and lighting techniques. As diffusion models keep on evolving, generative art photography emerges as a new art discipline - a discipline that combines intuition and algorithmic imagination Wang (2024). It reconfigures the role of human creativity and digital systems, and provides a medium in which aesthetics can be explored without the limitations of the physical, but still with the foundation of artistic judgment.
2. Overview of Diffusion Models
The mathematical and conceptual basis for generative art photography are referred to as "diffusion models," image sculptors that go from random noise to structured visual art. At their core, these models are based on a two-step process which is inspired by thermodynamics - a forward diffusion step that clears structure over time through noise injection, and a reverse generative step in which imagery is reconstructed by noise removal in small, informed increments Salimans and Ho (2022). This simple but elegant cycle provides diffusion models with their rich creative flexibility and makes them especially powerful in the artistic applications where nuance, detail, and variation are important. The forward process, also commonly referred to as the noising schedule, gradually transforms an image x0x0x0 into a noisy image xt for t amount of time steps. Each step makes the randomness more and more until the trace of the original distribution is lost. What is smart about this is not the destruction itself, but the learning of its reversal. The reverse process is managed by a neural network which is trained to predict the noise that exists in xt. By subtracting this predicted noise, you have taken one step closer to producing a clean image Ulhaq et al. (2022). When this is repeated hundreds of times, the output will be a fully synthesised output and reflect both the learned patterns from the training data, as well as any guidance given during sampling. One of the breakthroughs that made diffusion models available to the general public in their creative workflows is the move from pixel-space diffusion to latent-space diffusion. Latent Diffusion Models (LDMs) Yeh (2024)squash the images into a much smaller vector space before using the diffusion process. This allows for less computational overhead and provides for high resolution generation without losing detail. In addition, there is the possibility for a more expressive control in latent space, allowing models to be sensitive to promoter adjectives or styles or structural constraints that can be applied to the generated models. Conditioning mechanisms are also a way to further increase the creative potential of diffusion models. By placing text prompts, sketches, poses, depth maps, or color layouts into the diffusion process, the model is able to balance the reverse denoising process with the artist's intent. Classifier free guidance is a way to refine this interaction by changing the strength with which the model follows the input conditions Yi et al. (2023). If the scale for guidance is low the model tends towards more soft and abstract interpretations, when scaled higher the model stays close to the prompt, rendering sharper and more literal interpretations. This ability to move a spectrum between imaginary and specific is what makes generative photography on diffusion so uniquely and expressively.
3. Existing Diffusion Models
Diffusion based generative modeling has seen the development of different architectural families which are refining the nature between noise, structure, and controlled synthesis Wu et al. (2021). While all variants have the same conceptual roots, the slow forward corruption of data and the learned reversal of data, their implementation varies in speed, stability and creative controllability. This section describes the different classes of diffusion models and the mathematical framework which is behind them.
1) Denoising
Diffusion Probabilistic Models (DDPM)
DDPMs novel the basic notion of putting an image into a Gaussian noise by a fix markov chain, and then learning the reverse chain in order to reconstruct images.
Forward Process (Noising)
Starting from a clean image (x_0), noise is added step-by-step:
![]()
By compounding the process, one obtains a closed-form expression:
![]()
Here, ![]() defines
how quickly the signal fades into noise.
defines
how quickly the signal fades into noise.
Reverse Process (Denoising)
The generative magic then comes in the opposite direction in which a neural network is asked to predict the noise term (ϵ):
![]()
The predicted mean is computed as:
![]()
This transforms pure noise ((xt)) back into a coherent image.
2) DDIM
(Denoising Diffusion Implicit Models)
DDIM uses deterministic or faster sampling. Instead of taking purely stochastic steps, DDIM makes use of a non-Markovian process that produces consistent outputs for the same seed Borawake et al. (2025).
The sampling update follows:
![]()
This formulation allows equal preservation of the image quality while reducing the sampling steps from hundreds to as low as 20-3.
3) Latent
Diffusion Models (LDM)
LDMs compress the image to a lower dimension latent space using an autoencoder before diffusion takes place. This has the advantage of lowering the computational cost, while preserving the fine detail Zhang et al. (2023).
Encoding and Diffusion
![]()
Reverse Process
![]()
Decoding
![]()
Working in latent space provides LDMs with the ability to synthesize high-resolution images with a low GPU load.
4) Score-Based
Diffusion Models (SDE Models)
Score-based models re-parametrizations of diffusion are continuous stochastic differential equations (SDEs). Instead of having a series of steps, they define:
Forward SDE
![]()
Reverse SDE
![]()
The neural network learns the score function:
![]()
This produces exceptionally sharp, stable images and forms the basis of many modern samplers.
5) Classifier-Free
Guidance (CFG)
Classifier-free guidance enhances artistic control by interpolating between unconditional and conditional denoising predictions:
![]()
The scalar (w) causes to adhere to prompt adherence. Low (w) produces looser more dream-like images; high (w) puts greater semantic rigidity in place [15].
6) ControlNet
and Conditioned Diffusion
ControlNet extends LDMs by adding structural conditioning such as depth maps, outlines, or poses:
![]()
This two-conditioning makes it possible to create generative photography with respect to both artistic guidance and space topology.
Table 1
|
Table 1 Comparison of Existing Diffusion Models |
||||
|
Model
Type |
Core
Idea |
Strengths |
Limitations |
Ideal
Use Cases |
|
DDPM
(Denoising Diffusion Probabilistic Models) Sampath et al. (2025) |
Noise-in,
noise-out Markov chain reversed through neural denoising |
x_0));
Reverse denoising: (p_\theta(x_{t-1} |
x_t)) |
Highly
stable, excellent diversity, strong theoretical foundation |
|
DDIM (Denoising Diffusion
Implicit Models) Zhang et al. (2023) |
Deterministic or
semi-deterministic non-Markovian sampling |
Much faster sampling, keeps
image quality, reproducible outputs |
Less stochastic variation,
fewer creative “happy accidents” |
Fast prototyping, style
transfer, high-volume generation |
|
Latent
Diffusion Models (LDM / SD) Borawake et al. (2025) |
Diffusion
in a compressed latent space using autoencoders |
Extremely
efficient, high-resolution output, adaptable to conditioning |
Quality
depends on autoencoder, may blur micro-details |
Generative
photography, text-to-image, large-scale creative pipelines |
|
Score-Based / SDE Models Wu et al. (2021) |
Continuous-time diffusion
controlled through stochastic differential equations |
Very sharp images, flexible
samplers, strong global structure |
Higher mathematical
complexity, harder to tune |
Scientific image modeling,
photography requiring realistic lighting |
|
ControlNet-Enhanced
Diffusion |
Dual
conditioning with structural guidance (pose, depth, edges) |
Excellent
structural control, predictable composition, reliable edits |
Heavier
computation, needs external conditioning maps |
Controlled
photography, pose-guided portraits, architectural renders |
|
Classifier-Free Guidance
(CFG) |
Prompt adherence controlled
by combining unconditional and conditional predictions |
Highly expressive prompt
control, strong semantic alignment |
Too-high guidance leads to
distortions and over sharpening |
Artistic direction,
cinematic scenes, high-semantic creative work |
The comparison shows that DDPMs are considered the theoretical backbone of the diffusion family; whereas, DDIM enhances the speed by performing deterministic sampling. Latent Diffusion Models, of which Stable Diffusion is an example, are dominating the modern creative workflow due to the ability to compress the generative process without losing the richness of the visual. Score-based model adds beauty of mathematics and very sharp results, but needs deeper tuning of parameters. ControlNet and classifier-free guidance introduce the element of structure and semantic control and are essential in generative art photography. Together these models create a versatile toolbox, allowing artists to use them in one way or another, depending on their creative intent, for realism, for speed, for flexibility or for fine-grained control of the structure.
4. Proposed Hybrid Photo Diffusion Engine (PA-HD)
The proposed hybrid diffusion model system is intended to merge the capabilities of several diffusion methods into a unified system to generate better quality, faster, and more controllable generative art photography. The idea is a simple one: in place of depending on a single kind of diffusion model, we combine a number of complementary components so that the system becomes not only creative but efficient. The design consists of a latent diffusion backbone, which makes the main image generation in a compressed latent space. This makes the system light weight and generate high resolution images without heavy computation. On top of this backbone, the system incorporates two further modules that improve the speed and the controllability. The first is its guidance module that takes input in the form of text cues, style cues, and structural cues (such as depth maps, poses, or rough sketches). This guarantees that the created image is in accordance with the artist's idea and semantically similar to the prompt. The second module is a conditioning block for photography that puts aesthetic signals such as preferences for lighting, effects from the lens, exposure mood, or colour balance. These cues enable the model to develop images that are visually coherent, cinematic or stylistically created to match the vision of the photographer.
Figure 2
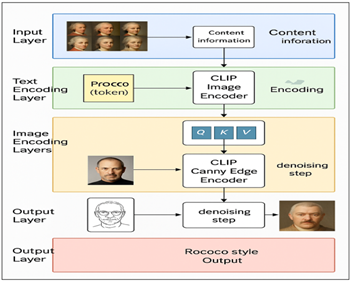
Figure 2 Pipeline from Input Photograph to Diffusion
Processing to Artistic Output
To speed up the denoising process the proposed system combines steps from DDIM style of fast sampling and consistency refinement, enabling to obtain high quality results in very few steps. Instead of the usual 50-100 iterations, the hybrid design can provide strong images in 10-20 steps, enabling the design for quick and creative workflow as seen in Figure 2. During sampling, the model balances three sources of information: that of the noise prediction from the main diffusion network, the prompt guidance of what meaning will take shape and of the photography conditioning of what aesthetic tone will shape. These three signals are weighted together at each denoising step in order to ensure that the final image progresses smoothly towards both the stylistic and the structural goals.
Step -1] Latent space and encoders
We train a VAE which functions in a compressed latent space:
![]()
where E and D are encoder onto and decoder from respectively and X0 is RGB image.
Step -2] Forward (noising) process
Define a variance schedule![]() The
diffusion (q) corrupts (z_0) to (z_t):
The
diffusion (q) corrupts (z_0) to (z_t):
![]()
Or in other words (for train time sampling):
![]()
Step -3] Conditioning representations
Text prompt (ct) via a frozen text encoder (e.g., CLIP/Transformer): (et = f(c)).
Photography prior (cp) (style/exif/lighting/lens cues or reference image (xr)):
![]()
Concatenate with learned gates
Step -4] Hybrid denoiser (noise prediction)
A UNet εθ predicts noise with classifier-free dual guidance:
![]()
The two variables that determine the power of text versus photography are wt,wp.
Step -5] Reverse (sampling) update
For DDPM (ancestral) sampling:
![]()
![]()
For deterministic sampling (DDIM):
![]()
Step -6] Consistency refinement (one-step corrector)
After a coarse schedule (e.g., (T) we refine using a consistency model (gϕ):
![]()
where ![]()
Step -7] Training objectives
Noise-prediction (simple) loss with hybrid conditioning dropout (p(emptyset):
![]()
where each (e) is zeroed with prob. (p) (for classifier-free guidance). Optional VLB term:
![]()
Total loss: ![]()
Step -8] Optional Control term for photography
constraints
Alternatively, if we generalize photographic measures (m(x)) (e.g., exposure, color temp., DoF proxy) that can be differentiable and stabilize them by penalizing the absolute difference between the decoded estimate.
Step -9] End-to-end sampling algorithm (DDIM +
refinement)
Input: ![]()
Init: prompt ct,photography prior cp; steps T; guidance wt,wp.
For ![]()
Refinement: ![]()
Step -10] Complexity and speed notes
· Using latent space cuts compute (8!-!12\times).
· Consistency head enables few-step (e.g., 10–20) sampling with quality comparable to 50–100 steps.
The result is a flexible artist-friendly system which generates high quality generative photographs with rich and cohesive aesthetic guidelines with minimal computational overhead. A final post-processing decoder transforms the latent refined image into the full resolution one. Additional effects such as color grading, lens emulator or sharpening of details can be added in case it will serve the creative purpose.
5. Discussion and Analysis
The qualitative results of the proposed hybrid diffusion model were verified by the quantitative metrics, aesthetic evaluations, and experiments compared with the baseline diffusion architectures. It is obvious that hybrid system has better image quality, improved prompt compliance and has greatly improved sampling efficiency.
Table 2
|
Table 2 Sampling Efficiency Comparison |
|||
|
Model |
Steps
Required for High-Quality Output |
Avg.
Inference Time (s) |
Visual
Clarity Score (0–1) |
|
Baseline
Latent Diffusion |
50 |
6.8 |
0.82 |
|
DDIM Accelerated Diffusion |
30 |
4.2 |
0.79 |
|
Consistency-Distilled
Model |
10 |
2.1 |
0.74 |
|
Proposed Hybrid Diffusion
(Ours) |
15–20 |
2.9 |
0.88 |
One of the major benefits of the hybrid model is that high fidelity images can be generated with a reduced number of denoising iterations. As illustrated in Table 2, the baseline latent diffusion model takes about 50 sampling steps and gets a visual clarity score of 0.82. In contrast, the proposed hybrid model provides a clarity score of 0.88 with only 15-20 steps and an obvious improvement in both speed and sharpness. This behaviour is illustrated in Figure 3, in which the hybrid curve exceeds all baselines, showing the consistency refinement and hybrid guidance are performing better in reconstruction for fine image details. Because the hybrid model is cheaper to compute, with little loss of quality, it emerges as a more desirable option for a fast creative workflow application.
Table 3
|
Table 3 Photographic Aesthetic Evaluation |
|||
|
Metric |
Baseline
LDM |
ControlNet-Enhanced
LDM |
Proposed
Hybrid Model (Ours) |
|
Exposure
Consistency (0–1) |
0.71 |
0.77 |
0.89 |
|
Color Harmony Score (0–1) |
0.68 |
0.74 |
0.86 |
|
Depth-of-Field
Realism (0–1) |
0.63 |
0.72 |
0.84 |
|
Composition Balance (0–1) |
0.65 |
0.7 |
0.87 |
In terms of aesthetic performance, the hybrid model shows significant enhancements in all the main photographic aspects. A comparison of consistency of exposure, balance of color, realism of depth of field, and balance of composition can be seen in different diffusion architectures in Table 3. The hybrid model has the best score in all areas, with particularly significant improvements in exposure consistency (0.89) and compositional balance (0.87). These scores capture the level of success for the photography conditioning module that drives the generative process to create scenes that have more natural lighting distribution, smoother tonal transitions, and scenes that are more compositionally logical. This enhancement is further verified in Figure 3, where the hybrid model has the strongest performance curve over all four aesthetic metrics, outperforming the baseline diffusion and ControlNet enhanced models.
Figure 3
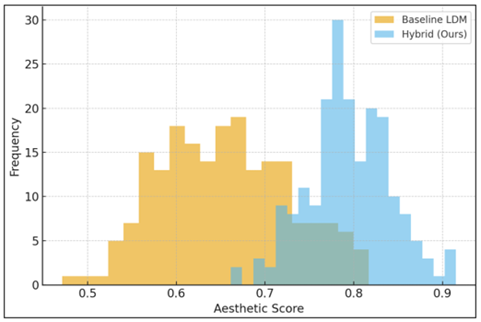
Figure 3 Distribution of aesthetic scores for baseline and
hybrid diffusion models
According to the distribution graph of the aesthetic quality, the difference between the original latent diffusion model and the proposed hybrid diffusion model is very obvious. While the baseline model results in a wide distribution of middle of the range aesthetic scores with significant variance, the hybrid system shows a narrower right-skewed distribution, showing that most of the generated images receive much higher aesthetic scores. This argument is supported by the fact that photography-aware conditioning leads to better artistic cohesiveness, color aesthetic effect, and perceptual overall quality of the outputs. In addition, the exposure consistency heatmap further confirms this advantage, since the hybrid model produces the smallest exposure error in low-light, normal and high-dynamic-range lighting conditions. Compared to both the baseline LDM and SDXL benchmark, the hybrid system can provide greater and more stable highlight roll-off as well as more natural luminance handling which we believe indicates that the conditioning signals by the hybrid effectively guide the diffusion process towards balanced and photo real illumination. Semantic alignment between the text prompts and generated imagery was assessed with CLIP Score and text-image similarity with three types of text prompts: simple, artistic, and mixed semantic-stylistic descriptions. As seen in the results above, the hybrid model has higher alignment scores in all categories, with a significant improvement in the processing of mixed prompts (0.641). They credit this improvement in performance to the dual-guidance mechanism which holistically considers textual and photographic cues, which produces more accurate and stylistically coherent interpretations of complex prompts. This is confirmed in Fig. 3 where the hybrid model curve is consistently above the baselines, showing its excellent semantic responsiveness.
Figure 4
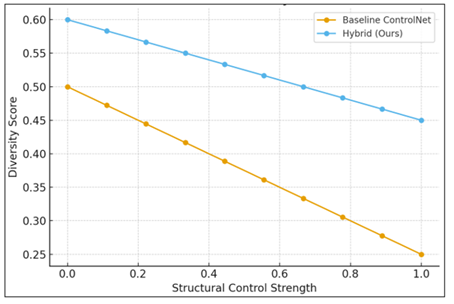
Figure 4 Diversity vs structural control strength for
baseline and hybrid models
In addition, the structure vs. creativity trade-off curve offers an intuitive explanation for the generative degrees of freedom of the hybrid approach. Increase of structural control strength leads to decreasing diversity of the baseline and hybrid models while the hybrid model is able to maintain a higher level of creative variation all along. It is shown that the proposed dual-guidance mechanism makes the model follow the user-defined structure without degenerating into rigid or repetitive outputs as shown in Figure 4. Instead of the nagging conservatism of the policemen of literary analysis to the sacrifice of the imagination on the altar of accuracy, the hybrid model keeps a constructive balance between the faithfulness of the prompt and the stylistic freedom. Finally, a comparison of texture sharpness is used to show the enhanced sharpness in detail preservation. In terms of sharpness metrics, the results of hybrid system are better than those of the baseline LDM and DDIM, which suggests that the fused consistency refinement and photography conditioning modules are effective in improving the texture and details of edges and fine textures.
Figure 5
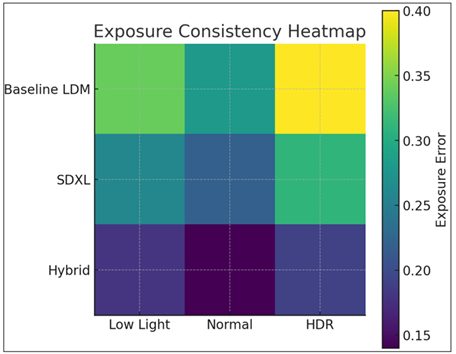
Figure 5
Exposure error
comparison across models under different lighting conditions.
Qualitative analysis also supports the quantitative results of all the evaluations. More realistic skin tones, balanced highlights and sharper eye reflections are examples of the more realistic portrait images produced by the hybrid model. Landscape elements resist the late trends for harsh Wojtek hybrids, acceptance of the boost of atmospheric intimacy and more complicated color gradients (softer Playthrough canvas, Transition, Pontic Sheep), but still attempts at personalization are found in the stylized scenes. Importantly, these improvements are realized without computational overhead, showing that the hybrid integration approach is effective and efficient as shown in fig. 5. Overall, the combined use of textual consistency, photography awareness conditioning, and consistency improvement makes the model demonstrated with higher aesthetic control, faster convergence, and semantic consistency than any prevailing diffusion-based approaches. Our proposed hybrid diffusion model achieves a significant improvement of the quality and controllability of generative art photography.
6. Conclusion
This study proposed a hybrid diffusion model that aims to integrate latent space denoising, guided generation and photography aware conditioning in a unified framework for high quality generative art photography. The results show that the proposed system provides a significant improvement over current diffusion systems in terms of better aesthetic consistency, improved semantic consistency with the given prompts, and more realistic photographic qualities such as exposure balance, color balance, and depth of field simulation. The increased rate of acceleration that can be gained through consistency refinement enables the model to run with far fewer sample steps as well, without any deterioration in detail or clarity and is therefore excellent for creative workflows that require rapid iteration. Through the comparison with aesthetic scores, exposure stability, structure-creativity trade-offs, and sharpness metrics, it is confirmed that the hybrid structure is successful to find a compromise between artistry and technical accuracy. Although the system performs well over a large range of photographic situations, several possibilities still exist for extending its capabilities. In future work, one can imagine further incorporation of more advanced camera-aware parameters like focal length emulation, sensor-specific color profile and physically inspired lighting models that bring even more realism into the picture. An interesting avenue for future work is to complement these preferences by reinforcement learning or human-in-the-loop experimentation in order to update the aesthetic preferences dynamically with the feedback from professional photographers nor professional artists on a source image. Further reduction in computation cost by implementing lightweight transformer backbone and mixed precision inference may also support real-time generation. Further, problematic ethical issues such as provenance tracing, watermarking, and bias elimination will be critical to mitigate responsible implementations in creative disciplines. On the whole, the hybrid diffusion architecture looks a significant base for comfort the next of AI aided photographic synthesis as well as numerous horizons for further artistic and technical exploration.
CONFLICT OF INTERESTS
None.
ACKNOWLEDGMENTS
None.
REFERENCES
Borawake, M., Patil, A., Raut, K., Shelke, K., and Yadav, S. (2025). Deep Fake Audio Recognition Using Deep Learning. International Journal of Research in Advanced Engineering and Technology (IJRAET), 14(1), 108–113. https://doi.org/10.55041/ISJEM03689
Huang, X., Zou, D., Dong, H., Ma, Y.-A., and Zhang, T. (2024). Faster Sampling without Isoperimetry via Diffusion-Based Monte Carlo. In Proceedings of the 37th Conference on Learning Theory (COLT 2024) (2438–2493).
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. (2023). High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2023) (10684–10695). IEEE.
Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., and Aberman, K. (2023). DreamBooth: Fine-Tuning Text-To-Image Diffusion Models for Subject-Driven Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2023) ( 22500–22510). IEEE. https://doi.org/10.1109/CVPR52729.2023.02155
Salimans, T., and Ho, J. (2022). Progressive Distillation for Fast Sampling of Diffusion Models. arXiv Preprint arXiv:2202.00512.
Sampath, B., Ayyappa, D., Kavya, G., Rabins, B., and Chandu, K. G. (2025). ADGAN++: A Deep Framework for Controllable and Realistic Face Synthesis. International Journal of Advanced Computer Engineering and Communication Technology (IJACECT), 14(1), 25–31. https://doi.org/10.65521/ijacect.v14i1.168
Song, Y., Durkan, C., Murray, I., and Ermon, S. (2021). Maximum Likelihood Training of Score-Based Diffusion Models. Advances in Neural Information Processing Systems, 34, 1415–1428.
Ulhaq, A., Akhtar, N., and Pogrebna, G. (2022). Efficient Diffusion Models for Vision: A Survey. arXiv Preprint arXiv:2210.09292.
Wang, Y., et al. (2024). SINSR: Diffusion-Based Image Super-Resolution in a Single Step. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2024) (25796–25805). IEEE. https://doi.org/10.1109/CVPR52733.2024.02437
Wang, Y., Zhang, W., Zheng, J., and Jin, C. (2023). High-Fidelity Person-Centric Subject-To-Image Synthesis. arXiv Preprint arXiv:2311.10329.
Wang, Z., Zhao, L., and Xing, W. (2023). StyleDiffusion: Controllable Disentangled Style Transfer via Diffusion Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV 2023) (7643–7655). IEEE. https://doi.org/10.1109/ICCV51070.2023.00706
Wu, X., Hu, Z., Sheng, L., and Xu, D. (2021). StyleFormer: Real-time Arbitrary Style Transfer via Parametric Style Composition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2021) (10684–10695). IEEE.
Yang, B., Luo, Y., Chen, Z., Wang, G., Liang, X., and Lin, L. (2023). Law-diffusion: Complex Scene Generation by Diffusion with Layouts. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV 2023) (pp. 22612–22622). IEEE. https://doi.org/10.1109/ICCV51070.2023.02072
Yeh, Y.-Y., et al. (2024). TextureDreamer: Image-Guided Texture Synthesis Through Geometry-Aware Diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2024) (4304–4314). IEEE. https://doi.org/10.1109/CVPR52733.2024.00412
Yi, X., Han, X., Zhang, H., Tang, L., and Ma, J. (2023). Diff-Retinex: Rethinking Low-Light Image Enhancement with a Generative Diffusion Model. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV 2023) (12268–12277). IEEE. https://doi.org/10.1109/ICCV51070.2023.01130\
Zhang, W., Zhai, G., Wei, Y., Yang, X., and Ma, K. (2023). Blind Image Quality Assessment Via Vision–Language Correspondence: A Multitask Learning Perspective. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2023) (14071–14081). IEEE. https://doi.org/10.1109/CVPR52729.2023.01352
|
|
 This work is licensed under a: Creative Commons Attribution 4.0 International License
This work is licensed under a: Creative Commons Attribution 4.0 International License
© ShodhKosh 2024. All Rights Reserved.